
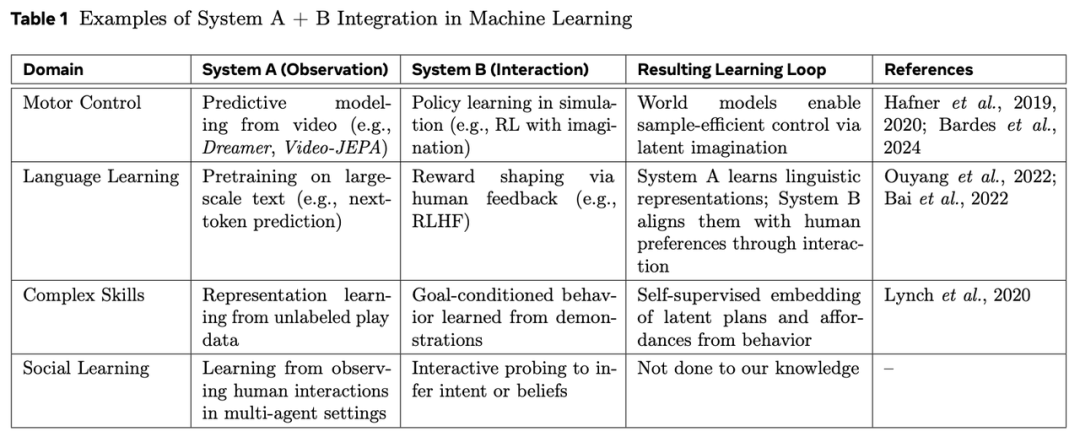
Meta AI Research:虚拟/可穿戴/机器人三位一体的AI进化路径
作者:Pascale Fung, Yoram Bachrach, Asli Celikyilmaz, Kamalika Chaudhuri, Delong Chen, Willy Chung, Emmanuel Dupoux, Hervé Jégou, Alessandro Lazaric, Arjun Majumdar, Andrea Madotto, Franziska Meier, Florian Metze, Théo Moutakanni, Juan Pino, Basile Terver, Joseph Tighe, Jitendra Malik
本文阐述了我们对具身AI代理的研究——这些代理以视觉、虚拟或物理形式存在,使其能够与用户及环境互动。这些代理包括虚拟化身、可穿戴设备和机器人,旨在感知、学习并在其周围环境中采取行动。与非具身代理相比,这种特性使它们更接近人类的学习与环境交互方式。我们认为,世界模型的构建是具身AI代理推理与规划的核心,这使代理能够理解并预测环境、解析用户意图及社会背景,从而增强其自主完成复杂任务的能力。世界建模涵盖多模态感知的整合、通过推理进行行动规划与控制,以及记忆机制,以形成对物理世界的全面认知。除物理世界外,我们还提出需学习用户的心理世界模型,以优化人机协作。
虚拟具身代理正在通过情感智能交互革新治疗与娱乐领域。例如,可穿戴代理(如AI眼镜)可能提供实时辅助与个性化体验,而机器人代理则有望解决劳动力短缺问题,并在非结构化环境中执行任务。除具身AI代理的技术挑战及我们的解决方案外,本文还强调了伦理考量的重要性,特别是隐私保护与拟人化问题,因为这些代理正日益融入日常生活。
未来的研究方向包括具身AI学习、改进多代理协作与人机交互、提升其社交智能,以及确保设计中的伦理实践。通过应对这些挑战,具身AI代理有望变革人机交互方式,使其更直观地响应人类需求。本文概述了当前研究现状与未来方向,旨在释放具身AI代理对人类生活的变革潜力。
日期:2025年6月30日
通讯作者:Pascale Fung
1 引言
2 具身人工智能代理的类型与应用
2.1 虚拟具身代理
2.2 可穿戴代理
2.3 机器人代理
3 具身代理的世界模型
3.1 多模态感知
3.1.1 图像与视频
3.1.2 音频与语音
3.1.3 触觉
3.2 物理世界模型
3.2.1 低级运动规划
3.2.2 高级动作规划
3.3 心理世界模型
3.4 动作与控制
3.5 记忆
3.5.1 现有记忆
3.5.2 世界模型的记忆挑战与目标
3.6 世界模型基准测试
3.6.1 最小视频对基准
3.6.2 IntPhys
3.6.3 因果视觉问答基准(CausalVQA)
3.6.4 世界预测基准
4 第一类:虚拟具身代理
5 第二类:可穿戴代理
5.1 能力分类
5.2 架构与模型
5.3 基准测试
5.3.1 目标推断基准
5.3.2 世界预测基准
6 第三类:机器人代理
6.1 能力分类
6.1.1 物理能力
6.1.2 “大脑”能力
6.2 架构与模型
6.2.1 基于解析模型的经典机器人学注释
6.3 基准测试
6.3.1 仿真基准
6.3.2 硬件基准
7 未来方向:具身人工智能学习
8 未来方向:多智能体交互
9 具身人工智能代理的伦理考量
10 结论
1 引言
Embodied AI agents是被实例化为视觉化、虚拟化或物理形态的人工智能系统,这种特性使它们能够学习并与用户及物理或数字化环境进行交互。这些具身智能系统需要具备以有意义的方式感知环境并采取行动的能力,从而要求其对所处物理世界有深度理解。与之形成对比的是,仅作为网络实体且无视觉形态的AI代理不具备具身性,而通过远程指令或预编程指令操作的机器人或无人机则缺乏真正AI代理特有的自主性和适应性。可穿戴设备的独特性使其区别于其他智能设备,因为它们整合了能够感知物理世界并在其中执行行动的AI系统。这种感知与行动的协同作用,使可穿戴代理从用户视角实现了具身化,有效模糊了人与机器之间的界限。正如哲学家Maurice Merleau-Ponty所言,“我不是在我身体中,我即我的身体”,强调身体不仅是心智的容器,更是我们存在不可分割的一部分。这一概念与AI领域的具身性密切相关——代理的具身性与环境被视为其认知过程的核心组成部分。基于上述理念,我们提出一个融合世界建模方法的具身智能代理框架,使这些系统能以更复杂且类人的方式推理并交互环境。
当前AI与机器人领域中,具身性服务于两个核心目标:(1) 物理交互 :它使AI系统能够通过直接行动(如机器人代理)或环境感知能力(如可穿戴代理)与物理世界交互;(2) 增强人机交互 :研究表明,具身代理能提升用户信任度。此外,一个新兴探索方向是(3) 类人学习与发育潜力 ,即通过丰富的感官体验使具身代理以类似人类的方式学习与发展。
实现能够自主学习并与人类及世界交互、辅助个人与职业生活的全自主AI系统,是AI发展的长期追求。从最早的规则型聊天机器人到AI呼叫中心助手、虚拟助手,AI助手的能力在每次迭代中不断扩展与优化。在线AI代理的出现是这一进程的最新里程碑。同时,AI的具身化呈现多种形式:从带虚拟形象的对话代理到可穿戴设备、机器人及类人机器人,每种形态针对不同任务与应用场景,虽需不同能力,但共享部分核心功能。
与前几代AI助手相比,AI代理更具自主性。它们能自主规划多步骤任务所需的行动路径、调用外部资源、协作其他代理,并通过显式查询或隐式上下文理解用户需求。具身代理还需代用户执行或协助其行动,这需要复杂的推理与规划能力。对世界的感知与行动规划能力被称为“world modeling”。
此外,代理需在需要进一步澄清或上下文变化时与用户对话。未来,代理将实现多代理与多用户的交互,这种人机交互需具备表达力且对社会与情境敏感,即代理需理解用户的“心智世界模型”。为支持物理与心智世界建模、推理及规划,具身代理必须具备短期与长期记忆。
当前AI助手向AI代理的演进,由LLM与VLM的技术突破驱动。开发者通过提示工程构建了基于虚拟形象、智能眼镜、VR设备及机器人和类人机器人的具身代理。大语言模型通过对话数据微调与RLHF,展现出卓越的语言理解与生成能力,并具备零样本执行多任务的能力。数百万用户的广泛使用使人们从最初对闲聊型聊天机器人的兴奋,迅速转向对其辅助工作与改善生活的期待。近期产业界与学术界发布的在线AI代理正是这一演进的结果。例如Meta眼镜可通过设备摄像头与麦克风感知用户所见所言(但尚未完全捕捉环境声音),调用Meta多模态AI代理。情境化AI的发展得益于LLM/VLM在感知、推理与规划中的提示工程应用。VLM可通过指令调优生成分步规划,LLM提示工程亦能指导机器人动作执行。
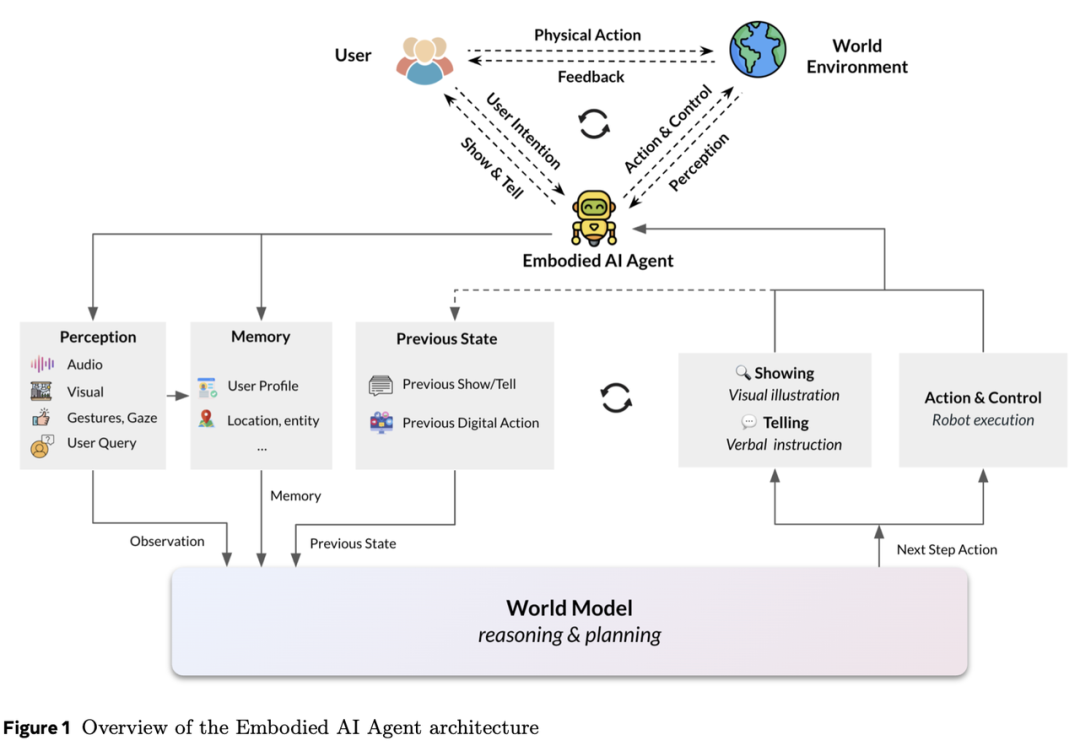
然而,生成模型的一个根本性缺陷在于其模型规模的低效性。用于预测下一个token或像素的生成模型在创意任务方面表现出色,但它们往往包含过多的文本或视觉细节,却遗漏了推理和规划任务所需的核心信息。推理与规划能力对于人工智能代理至关重要。为实现具身人工智能在准确性与效率上的平衡,我们提出了一种基于多模态感知进行合理动作与规划预测的世界建模方法。本文首先概述了不同类型的代理及其应用场景,随后描述了为具身智能代理提出的框架——世界模型,该框架包含感知、物理与心智世界建模、记忆以及行动与控制模块。我们将阐述基于生成模型的世界建模方法,以及可能更高效且可靠的替代性预测世界模型,并进一步描述三类具身智能代理(1)虚拟具身代理;(2)可穿戴代理;(3)机器人代理)的能力与模型。在各章节中,我们既介绍了各类代理的基准测试标准,也探讨了其潜在的研究方向。最后,我们描绘了具身学习的未来愿景,以及通过多智能体协作共同工作的代理家族。尤为重要的是,我们讨论了高度自主的具身智能代理面临的两个关键伦理问题:隐私与安全,以及拟人化倾向。
2.1 虚拟具身代理
VEA已成为各类对话任务中的关键组成部分,其情感表达能力可有效促进人机交互。这些代理可呈现多种形式,从虚拟二维或三维头像到搭载物理皮肤、具备类人面部特征及可控制面部表情与唇部运动的机电系统机器人。
VEA最常见的应用之一是AI治疗领域,用于为有需求的个体提供情感支持与陪伴。例如,Woebot和Wysa等AI聊天机器人被设计用于提供认知行为疗法和情感支持,通过具身对话代理创造更具参与感和共情的体验。
在AI治疗之外,VEA也在元宇宙和混合现实领域得到应用。在Second Life、Horizon Worlds和Sansar等虚拟环境中,VEA可作为导览员、导师甚至朋友,为用户提供更具沉浸感和互动性的体验。VEA还能丰富虚拟背景环境,例如通过NPC间的互动构建动态场景。这些代理可被设计为展现情感、共情与社会智能,成为虚拟社区的重要资产。
另一个探索方向是AI演播室头像。这些头像可用于影视及游戏制作,创造更具真实感和吸引力的角色。通过整合VEA到制作流程中,创作者不仅能塑造视觉惊艳的角色,还可赋予其情感智能,使其能够传达复杂情绪与细微表现。
此外,VEA将在虚拟与混合现实环境中发挥重要作用,通过助手、同伴及游戏NPC增强用户体验。这些头像将具备具身化特征,能够感知并理解虚拟世界,同时通过控制自身躯体及环境,与用户及其他虚拟代理协作完成任务。UNICORNs团队正致力于开发行为基础模型,以控制能以零样本方式解决复杂任务的虚拟具身代理。其中,Meta Motivo模型经过训练,可控制基于物理规律的人形虚拟角色,通过目标姿态、运动轨迹及优化函数提示完成全身任务。
除上述应用外,VAE还具有革新教育、客户服务和医疗保健等行业的潜力。例如,VAE可用于创建个性化学习体验,为学生提供自适应反馈与情感支持;在客户服务中,ECAs可通过富有同理心的类人交互提升满意度;在医疗保健领域,VAE可协助慢性病患者提供情感支持、用药提醒及激励信息,促进治疗依从性。
VAE的发展也催生了情感计算与社会机器人等新技术。情感计算利用机器学习算法检测与分析人类情绪,使VAE能相应作出反应。FAIR的Seamless项目旨在创建具有精准面部表情、手势与身体语言的情感化头像。社会机器人则专注于开发能以社交智能方式与人类互动的机器人,ECAs是其核心组件之一。
人类面对面交流是语言、声音与视觉线索交织的复杂过程,需要持续调整。为建模此类动态,我们正在开发双人基础模型,捕捉主动倾听、视觉同步与轮流对话等交互细节。Seamless Interaction数据集包含超过4000小时的双人互动大规模数据,为训练和评估这些模型提供了宝贵资源。基于此数据集,我们开发了一系列双人运动模型,既能生成面部与身体动作,又能响应用户的视听输入。这些模型展示了可控且情境相关的虚实交互潜力,为远程呈现、多模态视频分析等社会AI技术研究奠定基础。
虚拟具身代理正从AI治疗、元宇宙助手到AI演播室头像等多个维度改变我们的生活。随着该领域研究的持续推进,我们期待见证更多具备情感智能的VEA,进一步提升人机交互的质量与深度。
2.2 可穿戴代理
可穿戴设备区别于其他智能设备的特点在于:它们配备摄像头、麦克风和其他传感器,通过佩戴在用户身上的装置捕捉用户视角下的物理世界感知数据。可穿戴设备的独特性体现在其集成的AI系统能够感知物理环境并协助人类执行任务,这种特性使其与传统智能设备显著不同。这种感知与行动的协同效应使可穿戴代理与用户形成具身化融合,模糊了人机界限。
最典型的应用是Meta公司AI眼镜中的AI代理。用户可通过眼镜访问Meta AI系统进行信息查询、调用智能手机应用或与AI对话。多模态AI技术使眼镜能够看到用户所见场景,并听到用户所处环境中的声音。为充分发挥未来可穿戴设备的潜力,Meta的多个团队正在研发可穿戴AI代理。这类AI代理需要具备在物理世界中通过推理规划行动的能力。
一种方法是通过提示词引导LLMs和VLMs进行行动规划。然而,这种方法受限于模型不准确性和生成幻觉等问题。由于LLMs/VLMs被优化用于预测下一个文字或图像像素,其在长周期行动规划中效率低下。根据我们设计的WordPrediction基准测试,DMs已被证明效果有限,而VLMs虽优于LLMs和DMs,但仍会产生错误的行动方案。
Meta研究人员正在探索不同假设,包括基于Transformer和JEPA架构的替代性世界建模方法(详见第5.2节)。这种方法可能实现更高效、有效的长周期行动规划,使可穿戴设备为用户提供更高级的协助。另一种方法是训练VLMs直接根据以用户为中心的上下文预测佩戴者的目标。为验证这一新模型,研究人员创建了包含多种场景的基准测试,提供执行目标推断所需的上下文线索。
可穿戴代理通过提供实时指导显著提升人类任务表现,其核心功能可分为两类:指导与辅导。指导侧重于协助物理活动(如烹饪、组装家具或运动),共享用户的视听视角;而辅导聚焦于心智建模,通过AI代理提供认知任务指导(如数学问题解决)。
要实现有效指导或辅导,可穿戴代理需具备多模态感知能力,以理解物理环境和用户意图。此外,它们必须能非确定性地响应环境变化和用户意图,在长时间跨度内规划行动。这要求开发能动态适应情境并展现机器主动性的AI模型,而非单纯响应用户指令。尽管当前LLMs在解决数学问题方面表现出色,但其设计初衷并非作为辅导型AI。开发能提供个性化指导而不直接给出答案的AI导师,仍是亟待深入研究的领域。通过填补这一空白,我们可以创造更有效的可穿戴代理,增强人类能力并改善学习成果。
可穿戴设备的发展为教育、医疗、娱乐和科研等领域带来新机遇。例如,在教育领域可创建个性化学习体验,为学生提供自适应反馈和情感支持;在医疗领域可协助慢性病患者,通过提醒、激励信息促进治疗依从性;在娱乐领域可实现更沉浸式的虚拟环境交互体验。此外,可穿戴代理还能协助实验科学家的实验室工作,或作为科研助手支持其他领域研究。随着技术的持续进步,我们将见证更先进的可穿戴代理提供个性化协助、指导与辅导。
2.3 机器人代理
机器人代理是通过机器人实体在物理环境中独立或协作完成任务的AI系统。我们重点讨论通用型机器人代理,而非单一功能机器人。这类代理通过多种传感器(如RGB摄像头、触觉传感器、惯性测量单元、力/扭矩传感器、音频传感器等)感知环境,并通过动作控制机器人本体执行任务。其形态涵盖双臂人形机器人到轮式机械臂等特殊形态。我们预见机器人代理将以两种方式变革世界:1)自主执行多样化任务并与人类协作(常接管危险或繁重任务);2)通过现实世界的具身互动成为通用智能代理的基础。
让机器人在非结构化环境中自主协作完成日常任务是人类的长期愿景。具备通用技能的自主机器人可通过多种方式服务社会:缓解劳动力短缺、参与灾害救援(如地震或海啸)、支持老年护理、协助医院超负荷医护人员,以及分担家庭事务使人们有更多时间陪伴家人。要实现成功,机器人代理需学会在人类环境中自主执行任务,这推动着尽可能模仿人类身体与能力的人形机器人投资。
尽管机器人代理的核心价值在于其通过自主劳动支持人类的潜力,具身认知假说认为:唯有通过与真实世界的交互学习,才能培养出能理解现实的通用智能代理。通过感官输入在物理世界中实现具身学习,结合人类智能记录的学习,机器是否能获得类人智能,仍是活跃的研究领域。随着LLM作为基线模型的出现,研究人员得以探索具身学习在AGI(发展中的潜力。通过整合感官输入和真实世界经验,研究目标是构建更复杂、更接近人类水平的AI系统,使其以更有意义的方式与环境互动。
世界建模对于具身人工智能代理有效理解与交互环境至关重要。通过构建世界表征,这些代理能够学习推理、决策、适应与行动,最终实现更高效、自主且安全的运行。世界建模可提升效率、优化任务完成度并增强安全性。具身智能代理(如机器人或虚拟角色)通过与环境交互以达成目标并完成任务。为此,它们需要理解周围世界的结构、动态及物体间的关系,而这一过程正依赖于世界建模。
世界建模指创建环境表征的过程,供具身人工智能代理用于推理与决策。物理“世界模型”需捕捉环境的关键方面,例如:
物体及其属性(如形状、尺寸、颜色)
物体间的空间关系(如邻近性、距离)
环境的动态特性(如运动、时间变化)
基于物理规律的动作与结果因果关系
同时,具身代理需通过心理世界模型学习人类情境的内部表征。此类模型需涵盖以下方面:
目标与意图(包括动机、偏好和价值观)
用户的情绪及情感状态,以及这些情绪如何影响行为
社会动态,包括个体、群体与机构间的关系,以及文化规范、习俗和期望
对语言及非语言沟通的理解(包括语言、语调、肢体语言和面部表情)
通过构建能够捕捉这些方面的心理世界模型,具身人工智能代理可更好地理解人类行为、预见需求,并在多种场景下更有效地与人类交互。
具身人工智能代理需要世界建模以实现以下目标:
推理与规划 :世界模型使代理能够对环境进行推理并做出明智决策。通过理解物体间的关系及其动作的后果,代理可更高效地规划并执行任务。
零样本任务完成 :世界模型使代理能够适应变化的环境并应对新任务。通过学习世界表征而非机械记忆文本符号或图像像素,代理可响应新情境和意外事件。
人在环中的主动学习 :世界模型为持续主动学习与改进提供基础。代理通过与人类用户的交互,可不断完善对世界的理解并提升性能。
高效探索 :世界模型帮助代理高效探索环境。通过聚焦关键区域并避免不必要的动作,代理可更快地获取信息并学习。
世界模型使具身人工智能代理能够根据环境的多模态感知、用户画像与偏好、历史动作与交互进行推理与规划。因此,其需要感知模型、物理与认知任务规划以及情境化记忆(详见下文第3.1至3.6节)。
3.1 多模态感知
来自音频、语音、语言、图像和视频的多模态感知与理解对具身智能代理至关重要。代理根据每一步感知的信息采取行动。
3.1.1 图像与视频
具身代理必须具备先进的图像与视频理解能力。此能力需基于通用的视觉-语言模型。
图像与视频理解的核心是感知编码器 (PE),这是一种采用对比式视觉-语言目标训练的最先进视觉编码器。与依赖任务特定预训练的传统编码器不同,PE证明了通过精心扩展与稳健的视频数据整合,仅对比训练即可生成通用视觉嵌入,在广泛任务中表现优异。PE模型在零样本分类、检索、问答和空间推理等任务中达到最先进水平。
在此基础上,感知语言模型结合LLM的能力,构建了通用的视觉-语言模型。PLM基于PE,利用大规模合成与人工标注的图像及视频数据训练。该模型在无需蒸馏专有模型的情况下,性能与最先进开源模型相当,显著超越完全开源模型,在细节视觉理解(平均+9.1分)、视频描述(平均+39.8 CIDEr分)和细粒度视频问答(平均+3.8分)等任务中树立了新标杆。通过透明的模型设计、高质量数据与严格评估,PLM推动了多模态视觉-语言学习的可复现性研究。
3.1.2 音频与语音
可穿戴具身代理需要复杂的音频与语音理解能力以有效交互环境。代理需能准确检测并解读环境声音、非针对自身的对话以及直接面向自身的语音。在许多场景中,多模态理解可提高信噪比或成为必要条件(例如解析“用这个能做什么菜”中的“这个”)。关键的是,代理还需通过语音合成回应环境。基于深度学习的语音处理扩展至“Audio LLMs”,使可穿戴代理能理解副语言特征并实时响应用户意图。通过“检索”与“工具使用”功能,代理可将支持的查询或动作集成至音频LLM中。这些技术使可穿戴具身代理能在开放域提供更自然、直观的高质量体验。然而,实时性、轮替交互行为及整体交互的自然性(同时保持事实准确性等质量指标)仍是当前先进系统面临的挑战。
关键挑战
噪声鲁棒性 :具身代理常部署于嘈杂环境,需开发抗噪声语音识别系统以过滤背景噪声并聚焦用户语音。多通道音频处理可改善主语音与其他环境语音的分离。
语音多样性 :用户可能使用不同口音、方言或语言,要求代理具备适应性以理解多样化语音模式。区分佩戴者面向服务的语音与面向第三方的语音尤为困难,因两者均来自同一声源。
计算资源限制 :可穿戴设备通常处理能力、内存与电池寿命有限,需开发高效的音频与语音处理算法。
工具使用、检索增强生成与事实性 :生成模型虽在小领域表现良好,但在扩展至广域时维持事实性并支持工具使用仍具挑战。
未来方向
边缘人工智能 :开发可在本地处理音频与语音数据的可穿戴代理,降低延迟并减少对云服务的依赖,同时解决隐私问题。
个性化 :创建能学习并适应个体用户语音模式与偏好的代理,使其比通用模型提供更优体验。
多语言扩展 :使可穿戴代理支持多语言理解与响应,提升全球可用性,甚至覆盖非书面语言或无法读写用户。
3.1.3 触觉
人类(实际上所有动物)都具有触觉,并高度依赖触觉与环境进行有目的的交互并从中学习。在人类中,触觉提供了一种补充视觉的感知方式,其作用频率高于视觉。它通过提供接触感知来完善视觉感知,尤其在操作物体时,当存在遮挡(例如打开袋子时,或手部本身遮挡了待操作物体)的情况下,具身智能体将从触觉中受益。然而,触觉不仅提供接触感知,还能提供作用于环境的力信息,这在操作需小心处理的物体或需要物理辅助人类(例如老年人护理)时至关重要。触觉处理的重要组成部分是通用触觉编码器,如Sparsh,可处理触觉信号并实现力估计、物体滑动检测、纹理识别、物体姿态及抓取稳定性预测。
通过解决这些挑战并利用这些技术,可穿戴式具身智能体能够提供更自然、直观且高效的用户体验。
3.2 物理世界模型
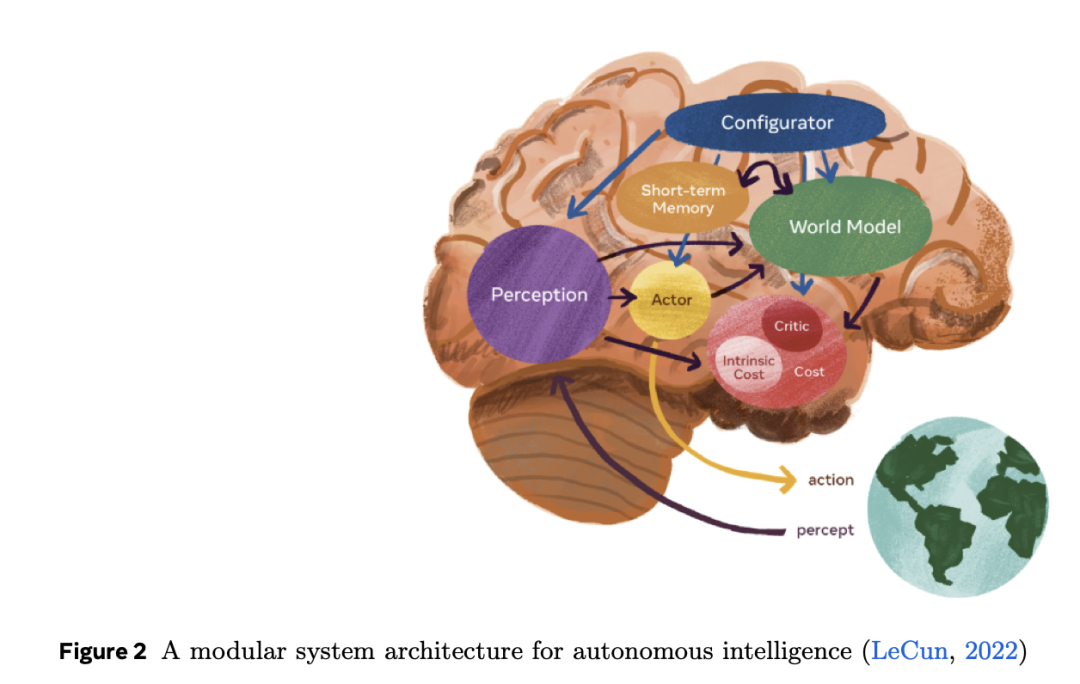
要在物理世界中行动,具身智能体必须理解这个世界。我们关注世界模型的实用原因是规划能力。一个需要完成明确任务的具身智能体(例如修理自行车、折叠衣物、引导用户完成食谱)不能仅依赖确定性或记忆化的计划,它必须能够想象环境在不同行动下的演变(以及变化的环境和意图),评估这些假设的未来状态,并选择预期成本最低的行动序列。监督式行为克隆只能模仿已观察到的行为;RL则需要在真实物理环境中试错,并依赖明确可验证的奖励信号,这极难获取。相比之下,LeCun的AMI架构提出了清晰的操作范式:世界模型在候选行动下推进环境演化,成本模块评估每个假设未来,MPC风格的规划器仅执行最低成本计划的第一步,随后通过新观测值重新规划。可复用的世界模型使智能体能在新情境中实现零样本规划,实时修正计划,并跨任务迁移而无需重新训练。
两类设计考量塑造了每个世界模型。第一是时间与行动语义的粒度。一方面,低级动力学涉及机器人行动中每几毫秒变化的关节扭矩;另一方面,人类尺度的行动(例如“插入电池”)可能持续数秒或分钟。第二是建模方法。生成模型通过像素空间重建下一观测,虽表达能力强但计算成本高,因其需捕捉场景中的每个低级细节。具有多模态感知能力的LLM以文本形式生成计划,但易因训练数据中的虚假关联产生幻觉。相反,联合嵌入世界模型直接在抽象潜在空间中预测世界,既高效又稳定,但其有效性取决于抽象对任务因果结构的捕捉程度。
3.2.1 低级运动规划
借鉴人类发展运动规划与控制能力的方式,使用学习到的世界模型以身体质心、肢体及操作工具(手部或末端执行器)的动力学层级(低于20Hz)发送指令是合理的。这类世界模型在先验上过于庞大,无法以更高频率调用。此类模型应向高频控制器发送指令,以优化关节扭矩层级以满足指令行动(即机器人的“肌肉精准控制”,参见第6.2.1节)。V-JEPA 2-AC采用了这一方法(如图3所示),其将行动表述为末端执行器(x, y, z)位置与方向的增量,随后由机器人低级控制器优化实现该指令运动的轨迹。
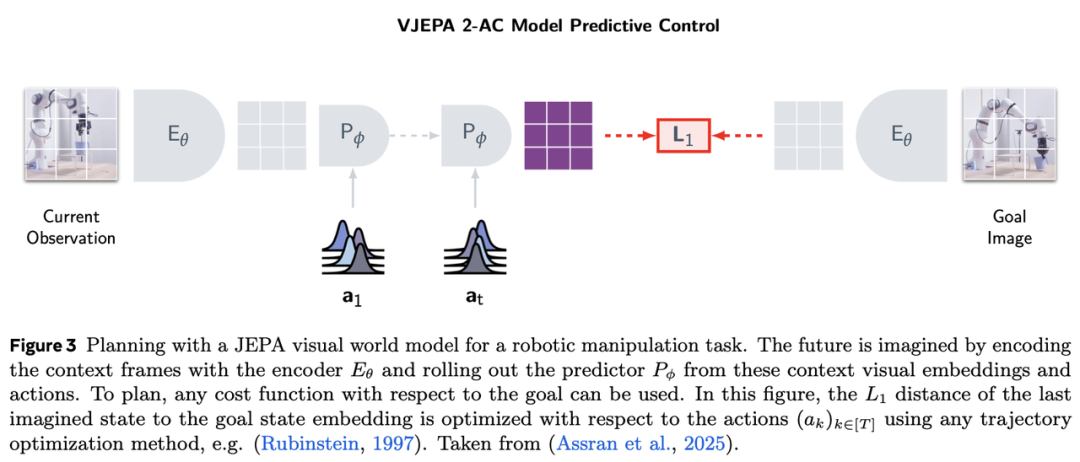
视觉世界模型。经典机器人学主要依赖本体感知信息与分析模型来估计机器人及环境中物体的位置。而视觉输入为机器人控制器提供了更丰富的信息,远超经典控制中使用的其他传感器输入。因此,从视觉输入以及其他潜在的本体感知或外感知输入中学习世界模型,对于全面且通用地理解物理世界不可或缺。此外,使用学习到的视觉世界模型可连接高级世界模型,利用其对视觉感知的语义理解来规划更抽象的任务。正如后续所述,当使用VLM作为高级世界模型时,可在抽象的视觉与文本表征空间中规划,从而指导运动规划器。视觉输入是最高带宽的输入,使婴儿能够学习外部世界运作规律并构建物理世界模型。
基于世界模型的规划。在规划中,我们可使用学习到的预测模型以达成目标状态,或最小化未来规划状态的成本函数。成本函数可包含目标状态的距离项(在图3中,我们采用嵌入间的距离)以及其他需最小化的惩罚项与目标项。对未来行动的优化器可以是基于梯度的(当学习模型可微分时可行),也可以是非梯度的。规划(系统2)比调用策略(系统1)更耗资源,但更可能在训练分布外实现零样本泛化。学习到的世界模型已被用于两种场景:1)在世界模型生成的轨迹上训练策略;2)使用学习模型进行基于模型的规划。
生成式世界模型。为从视觉输入中建模物理世界动态,生成式视频模型被训练以生成最可能的未来帧,其条件可能包括无输入、文本提示或行动。尽管此类模型已被用于在模拟视频中训练策略,但其是否能以零样本方式控制智能体仍有待明确。
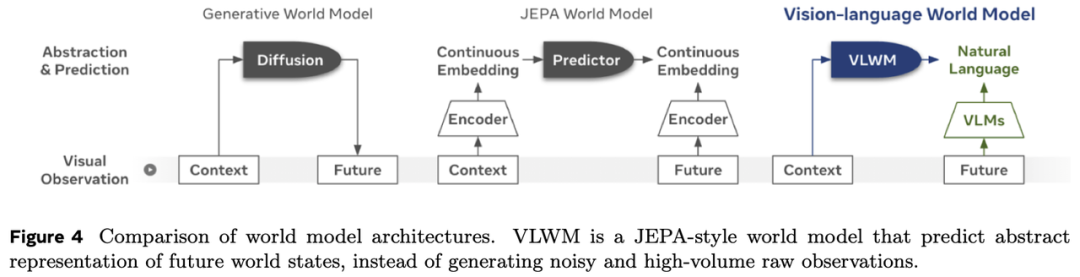
联合嵌入预测世界模型。使用预训练视觉编码器并训练世界模型在该嵌入空间中进行预测,是学习视觉世界模型的最主流方法。视频生成模型通常依赖连续或离散变分自编码器(VAE、VQ-VAE)来实现高视觉保真度。相比之下,面向控制智能体或预测未来分割图等下游任务的世界模型,则受益于在高层潜在空间中预测未来状态。
3.2.2 高层动作规划
高层动作规划指具身智能体生成、组织并推理跨越长时间跨度的动作序列的能力,这些动作具有更高语义抽象性。若低层模型使智能体能抓取物体或导航短距离路径,高层模型则使其完成复杂目标导向任务,如准备餐食、组装设备或引导用户完成多步骤流程。
这些模型运行在人类相关的时域尺度上——通常以秒或分钟为单位——必须考虑因果依赖性、时间顺序和任务分解。不同于对即时输入的反射性响应,具备高层规划能力的智能体会预判未来状态、推断意图,并协调情境化有意义的动作序列展开。
高层规划的一个关键优势在于抽象化能力。高层规划器不处理原始感知数据或低层运动指令,而是基于符号化、语言化或抽象表征进行推理,这些表征紧凑编码了语义状态转换。例如,规划器无需理解每个动作级别的过渡,而是推理"抽屉已打开"或"电池已安装"等状态转换。这种抽象显著缩小了规划搜索空间,并改善了跨任务泛化能力,因为抽象动作往往在不同情境中重复出现。
这种推理能力对辅助机器人、增强现实等具身智能应用至关重要。然而,高层动作建模仍面临多重挑战:首先,程序性活动的多样性和丰富性使高层动作难以模拟或穷举任务变体。任何合成环境仅允许特定任务、领域和环境限定的行动集合。其次,与物理情境的整合是另一挑战,尤其在动态真实世界环境中。动作级别或操作级别的行为后果易于感知,但高层动作对环境的影响可能难以动态模拟。最后,开放环境下高层动作规划缺乏程序合理性或任务成功的客观评估指标。即使在封闭环境中,成功率、平均交并比或固定短时域(三至四步)的平均准确率等指标,也难以推广到真实用例。因此,高层动作规划处于感知、推理和语言理解的交汇点,需要能模拟物理世界程序性知识的模型。
3.3 心智世界模型
人类的心智世界建模是创建包含物体、事件及关系的心理表征的过程,这一认知能力在推理中起核心作用:通过模拟情境、预测结果、进行反事实和因果推理,从而做出明智决策。它也是抽象化与泛化能力的一种体现。人类通过进化及多种形式的具身学习、体验学习和监督学习来构建心理模型。我们认为智能体需学习人类心智状态,以更好地辅助和协作人类。
物理世界模型是AI智能体构建的用于理解、预测和推理外部世界的内部表征,而心智世界模型则是智能体对人类用户或其他AI智能体心智状态的表征,这对"ToM"推理至关重要。心智世界模型在人机交互任务(如辅助或教学)及多智能体协作中尤为重要。
典型心智世界模型包含以下核心组件:
-
信念:表征人类对世界的知识或观点
-
目标:表征用户期望的结果或目的
-
意图:表征人类或智能体为达成目标的计划或行动
-
情绪:表征人类的情感状态,影响其行为和决策
通过整合这些组件,心智世界模型可应用于多个场景:
-
预测目标与意图:通过预判用户意图,心智模型可使智能体主动提供协助或指导
-
推断信念差异:当对话中某人误信物体位置而另一人知晓真相时,心智模型可推断该认知差异并预测行为
-
预测情绪反应:心智模型可预测用户对特定信息或行动的情绪反应,使智能体调整策略以更好支持需求
赋予AI智能体心智世界模型具有多重优势:
-
通过表征和推理用户的信念、目标、价值观及偏好,促进人机协作效率与效果
-
增强对用户心智状态的理解,实现更有效且富有同理心的交互
-
使智能体能主动战略性规划对话策略,引导用户达成目标并提升任务效能
给定感知刺激输入Xp(含一个或多个人类主体的图像、视频),主体s在X中的心智状态Xm,s包含对其以下方面的文本描述:
-
对特定感知场的注意力
-
短期记忆
-
长期记忆(含相关世界知识)
-
短期意图
-
长期目标
-
情绪
-
对物理世界状态的信念
-
对其他主体心智状态的信念
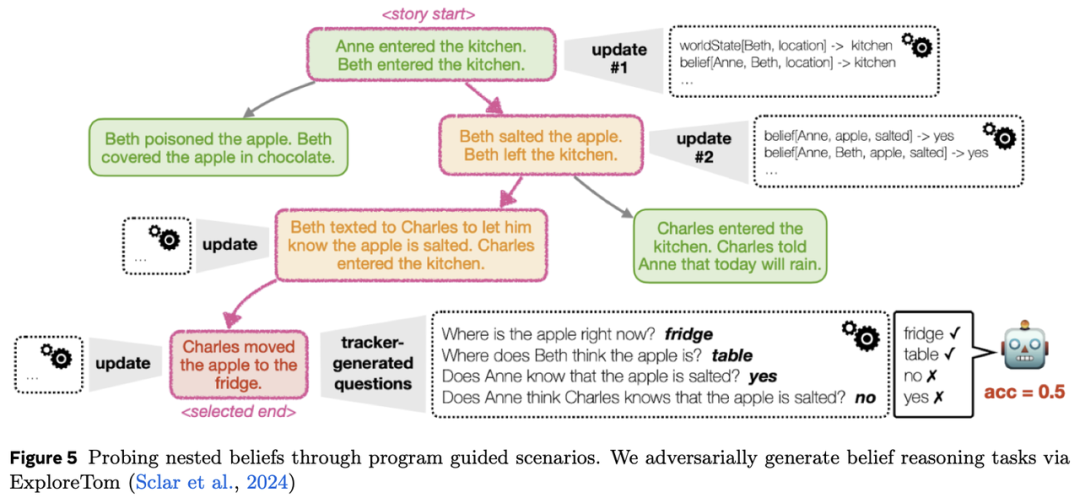
此列表非穷尽,心智状态模态的维度可根据应用场景灵活调整。近期多项研究揭示了当前AI模型(如大语言模型)在理解他人心理状态方面的局限性。基准测试如ToMI和Hi-ToM主要聚焦心智状态跟踪,但存在显著限制:ToMi仅支持有限动作集,Hi-ToM虽略有扩展但交互形式受限。近期ExploreToM通过程序化场景构建对抗生成基于信念的推理任务取得进展。通过将心智理论建模为主动探询挑战——智能体需提问或解释信念更新——ExploreToM强调交互过程中动态结构表征的重要性。这一方向补充了我们关于心智世界模型的更广泛议程,即从单轮推理转向多轮协作中动态构建和优化内部模型。尽管ExploreToM聚焦评估,未来研究需探索将潜在信念跟踪和社会反馈整合到学习循环中,以实现开放场景下动态适应他人视角的智能体。
3.4 行动与控制
不同形态的具身智能体在不同空间执行行动:数字空间中的2D虚拟智能体;3D虚拟智能体在AR或VR环境中执行行动;可穿戴智能体在现实世界中进行程序化规划,并向用户展示或告知需要执行的任务及时间;机器人智能体则必须在物理世界中控制机器人的行动。
虚拟具身智能体在数字环境中呈现,并通过VR头戴设备或AR眼镜进行可视化,以实现与用户的个性化交互。这类智能体通常使用可控的运动模型,能够调整情感反应和面部特征的表达水平,并生成用于肢体语言的手势。社会智能是VEA的重要能力,智能体需控制语言(语音模型)与非语言(运动模型)行动之间的协同。
可穿戴智能体通过视觉“展示”和语音“告知”指导人类行动,或在智能设备上执行操作。当前的人机交互范式以用户主动发起任务指令为主,由智能体端到端执行行动。一些研究也表明,智能体可根据上下文自主行动(机器发起模式)的优势。我们提出,在指导人类行动时,智能体需全面掌握“展示什么、告知什么”以及“何时展示、何时告知”的混合主动权。具身智能体需与人类充分互动,既支持直接查询,也需预测用户需要指导的时机。
机器人智能体通常通过两种方式控制机器人硬件:直接在关节层级发送位置、速度和/或力/扭矩指令至每个执行器;或更抽象的层级(如机器人躯干/基座的期望(相对)位置、末端执行器(手部)的(相对)位置、适用情况下的脚部位置),随后将这些指令转换为关节层级控制命令。对于每个行动空间,机器人系统需实现控制器,以从选定的行动空间按需计算低层指令(通常是期望的关节力/扭矩),确保机器人安全运行。
3.5 记忆
具身智能体涉及的世界模型核心要素之一是记忆。它贯穿智能体的处理过程,尤其是记录智能体与世界的交互,并将其整合为内部表征,从而有效参数化世界模型。此处简要回顾Transformer架构中的记忆形式,以及构建能赋能具身AI智能体的记忆所需的关键特性与挑战。Pink等人的立场论文强调了情景记忆对智能体的重要性,并补充了不同类型记忆的观点。
3.5.1 现有记忆形式
在主流神经网络中,可区分三种记忆形式:
固定记忆 :模型权重。这种记忆形式由神经网络模型的参数化函数定义,通过预定义(固定)数据集训练获得,因此包含数据集中的知识。训练完成后,推理阶段权重固定。其局限性包括:
若需添加新知识或适应新任务/领域,可通过微调实现,但需权衡获取新知识与遗忘预训练阶段注入知识之间的平衡。实践中,对话智能体通过微调可有效实现对齐(即调整模型以更符合预期,包括提升安全性)。
权重数量预先固定,容量恒定。微调或LoRA不会增加模型容量。
工作记忆 :通常指神经网络激活值的子集。数学上,将神经网络视为组合函数,工作记忆是中间函数的输入和输出。其写入过程即计算这些中间函数,无需反向传播,因此速度较快。典型例子包括:循环神经网络(RNN)的内部状态、状态空间模型(SSM)。对Transformer而言,对应的是Key-Value Cache。在此框架下,可分为可变记忆(如RNN状态,可更新修改)与不可变记忆(如KV缓存,一旦计算不可修改,便于索引与缓存)。不可变记忆的读写简单(无需平衡新增内容与遗忘),但未压缩,需线性增长存储所有潜在有用信息,且读取操作消耗的FLOPs随数据量增加而上升。
外部记忆 :指架构之外存储的原始信息,通过特定机制访问,包括RAG,这是最常见的外部记忆形式。某种程度上,思维链也可视为外部工作记忆,此时输入输出空间本身充当记忆载体。外部记忆通常未压缩,但通过嵌入搜索快速访问相关子集。
3.5.2 世界模型记忆的挑战与目标
研究需创造一种可随环境交互扩展的新型记忆——“情景记忆”。
现有记忆的局限性 :固定记忆容量受限且写入缓慢(依赖反向传播);KV缓存随交互时间线性增长,难以长期扩展;外部记忆虽能避免计算复杂度爆炸,但未压缩需存储所有交互,并需中间处理才能利用知识。
情景记忆的多目标性 :
个性化 :为现有架构增加显式记忆是实现个性化的简单方式,可将模型特定区域专用于个性化。这涉及模型适配技术(如适配器、LoRA)。智能体需在内存与训练资源效率上优化个性化,理想情况下通过压缩方式存储用户交互历史。
终身训练 :现有架构依赖预训练/后训练/推理范式:预训练阶段通过代理目标注入知识;后训练阶段适配用例并调整对齐;推理阶段模型冻结,仅定制KV缓存。研究需突破这一限制,使模型在交互中持续学习。当前难点在于资源需求随交互时间线性增长,需设计亚线性扩展的记忆容量机制。测试时训练策略与前向读写方法的探索将支持这一目标。
3.6 世界模型基准
3.6.1 最小变化视频对
最小变化视频对(MVP)基准旨在通过解决现有评估中的常见缺陷——因利用捷径导致性能虚高问题,更稳健地评估视频-语言模型的物理与时空推理能力。MVP 包含 55,000 组选择题形式的视频问答对,聚焦于真实世界与模拟场景中物理事件的理解,涵盖第一视角与第三人称视角视频、机器人交互以及认知科学启发的直觉物理任务。该基准的核心特征是包含最小变化视频对:每组视频几乎完全相同,但配对相同问题时需给出不同正确答案。这种设计迫使模型依赖精细的物理理解,而非依赖表面视觉或语言模式。基准结果显示,当前视频-语言模型与人类存在显著性能差距——最先进模型仅实现 40.2% 的准确率,远低于 92.9% 的人类基线水平,甚至接近 25% 的随机猜测率,突显了物理推理与泛化能力的持续挑战。

3.6.2 直觉物理基准直觉物理基准2(IntPhys2)是一个基于视频的评估基准,旨在评估模型对直觉物理的理解能力,延续早期 IntPhys 框架。其目标聚焦宏观物体的四项基本原理——恒存性、不可变性、时空连续性与实体性,灵感源自儿童早期认知发展研究。IntPhys2 采用预期违反范式,呈现可控虚拟场景对比物理合理与不合理事件,挑战模型识别并推理这些差异的能力。基准结果显示,尽管当代视觉模型可处理基础视觉特征,但在深层物理推理任务中表现挣扎,复杂测试案例中常处于随机水平;而人类参与者则接近完美表现。这些发现揭示了当前系统在捕捉核心物理直觉上的局限性,强调了为具身智能体实现类人理解需更复杂建模方法的重要性。

3.6.3 因果关系视频问答
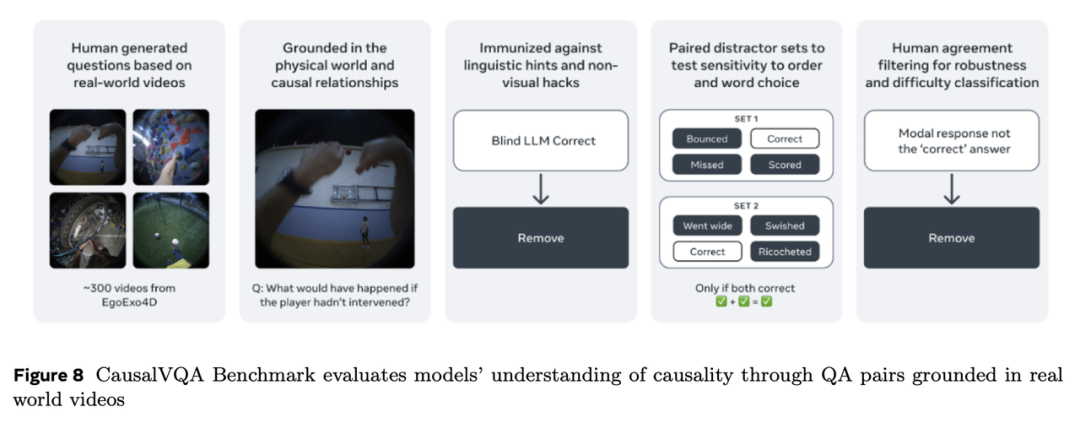
因果关系视频问答(CausalVQA)旨在通过现实场景中的因果推理视角评估视频问答(VQA)系统。不同于以往侧重低级感知理解或专注于物理推理合成环境的 VQA 基准,CausalVQA 通过基于自然视频场景的多样化挑战性问题弥合这一差距。该基准包含五类不同问题类型——反事实、假设性、预判、规划与描述性问题,综合评估模型推理因果关系、预测行为结果及理解时间动态的能力。为确保评估稳健性,数据集采用防止捷径利用的设计策略,迫使模型依赖真实的视觉与时间理解而非表面文本模式。实证评估显示,最先进多模态模型在人类对比中显著表现不足,尤其在预判与假设性推理任务中,凸显了当前系统在捕捉因果与时间结构上的局限性——这对具身智能体的有效世界建模至关重要。
3.6.4 世界预测基准
评估AI模型执行高层行动规划的能力,需要能够反映人类自然进行的世界建模类型的基准测试——即通过推断和推理抽象世界状态来指导行为。尽管此前的AI基准测试主要集中在低层世界动态或机器人控制上,WorldPrediction基准测试引入了一个以程序化规划和时间抽象为核心的全新评估框架。这对于可穿戴代理尤其重要,因为它们必须解读动态视觉环境并预测用户需求,以提供及时且符合情境的协助。WorldPrediction包含两项任务:识别初始与最终状态之间的正确行动(WorldPrediction-WM),以及从干扰项中选择正确的行动序列(WorldPrediction-PP)。与依赖低层视觉连续性的数据集不同,该基准测试引入了“行动等效项”,以隔离高层推理与感知捷径的影响。该框架基于形式化的部分可观察半马尔可夫决策过程(semi-MDP),支持包括生成模型在内的AI系统间的稳健比较。大量人类验证结果证实了该基准的难度:尽管人类表现接近完美,当前最先进的模型在WM任务上仅达到57%的准确率,PP任务则为38%。
对话式AI在辅助人类任务方面有着辉煌的历史。其发展催生了多代AI助手,从电话客服代理到智能设备上的虚拟助手。2010年代,得益于神经网络模型能力的提升,聊天机器人被开发用于与人类用户进行多轮纯对话交互。随着编码-解码架构(尤其是Transformer架构)的持续改进,这类对话代理的质量实现了跨越式提升。ChatGPT是首个在对话数据上微调的LLM,它不仅能够与用户进行对话,还展现出新兴的多任务处理能力。过去一年中,针对特定任务的对话式AI代理以“AI代理”的新形态涌现。然而,与Siri和Alexa一样,它们并未以任何物理形态具身化。
与此同时,微软的Tay和小冰曾以“拟人化”少女形象呈现,并配有卡通化的人脸。这种以虚拟角色具身化的对话式AI代理,与“无面孔”对话式AI代理并行发展,旨在增强人机交互体验。研究表明,当能力相当时,人类更容易与能通过表情互动的虚拟形象建立联系,而非与无面孔的聊天机器人。
现代AI虚拟化身不同于过去的卡通人脸,其设计目标是通过恰当的面部表情和嘴唇动作模拟人类情感表达。其面部可通过代码控制,并基于学习或手工设计的面部驱动形变。类似地,逼真的身体外观(躯干、发型、服饰)和手势可通过视觉输入捕捉或学习实现。
Ma等的研究表明,通过融入人格驱动的情感表达可提升虚拟化身的情商。换言之,赋予其一致且独特的人格特征,能传递更强的情感能力感知,并更好应对用户挑战。另一项研究指出,作为AI代理的新形态,AI虚拟化身具有增强可信度和接受度的优势,可实现类人交互与参与。但同时也会引发对心理影响、歧视和偏见的担忧。
另一个重要维度是,具身化的AI虚拟化身可在VR和MR环境中与用户互动。例如,在VR中玩游戏的虚拟伴侣或混合现实中的虚拟宠物。此时,AI虚拟化身需具备感知和理解周围环境的能力,并以符合其具身形态的方式与环境互动。
一种训练虚拟具身代理有效交互的方法是采用RL范式,其核心是学习控制代理身体的“策略”,以优化形式化任务目标(如赢得游戏)的奖励函数。该方法在基于物理的角色动画中广受欢迎,通常将物理模拟器与RL算法结合,生成具有高度真实感的完全反应式行为。这种方法有望完全自动化创建能实现逼真、一致行为并解决复杂任务的AI虚拟化身。
可穿戴设备代表了人机交互的范式转变,因其独特的具身化特性而区别于传统智能设备。这些设备通过集成摄像头、麦克风及多种精密传感器直接佩戴于用户身体,能够捕捉用户周围物理环境的第一视角(egocentric perspective)。这一第一视角从根本上改变了人工智能与人类体验的关系,形成了研究者所称的“共享感知场”。
可穿戴设备在技术生态中的独特性源于其从用户视角感知世界的能力:它能看见用户所见,听见用户所闻。与需要显式交互的固定智能设备甚至移动手机不同,可穿戴AI系统可通过这一第一视角持续监测并解读用户环境。这种持续感知能力实现了无需用户持续干预的情境感知型环境智能。
Meta的AI眼镜是可穿戴AI技术最具代表性的应用之一,体现了先进硬件能力与复杂AI系统的融合。这些眼镜允许用户通过自然交互方式无缝访问Meta AI,从而请求信息、控制智能手机应用,并与嵌入式AI助手进行对话交互。AI系统的多模态特性使眼镜能够通过特定语音指令或物理手势感知用户的视觉场景和听觉环境,从而打造情境感知型助手。
5.1 能力分类
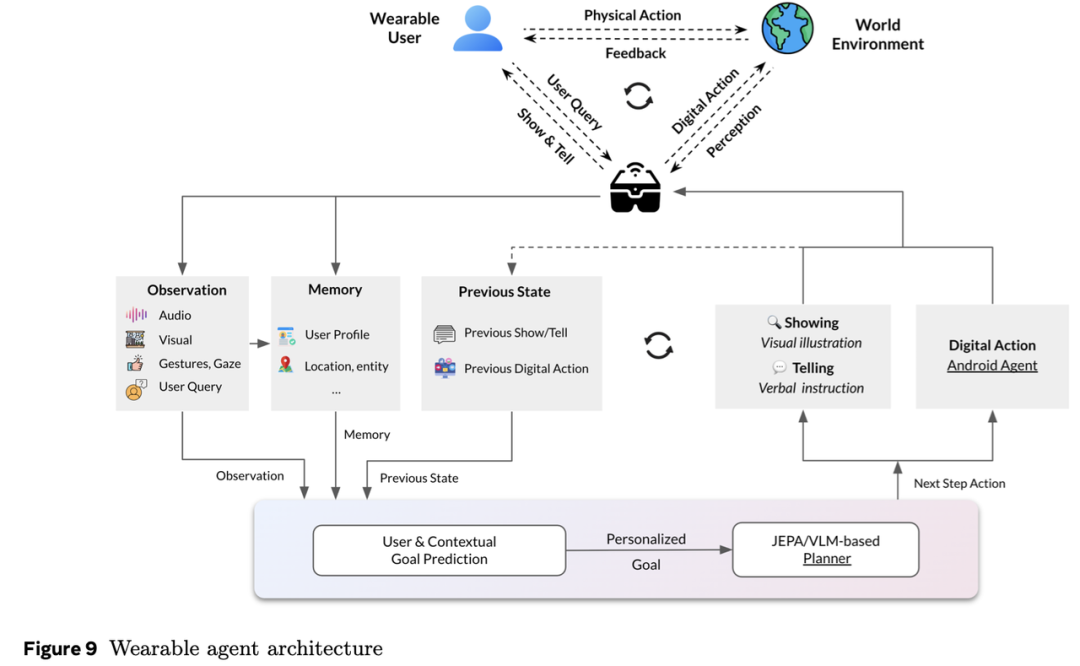
一款旨在辅助和增强人类能力的可穿戴智能代理,需要具备一系列先进功能,以有效预测并支持用户需求。基于超感测与感知技术,该代理应能通过显性指令和隐性情境线索,预判用户下一步要执行的任务。其核心能力包括物理/心理双世界规划与执行、个性化、记忆、社交智能、数字工具与界面导航,以及物理工具/设备/机械使用的指导。在物理/心理双世界规划与执行方面,代理需能够对物理环境建模并理解用户与其的交互,同时模拟用户的心理状态(包括目标、偏好和意图)。代理还应能长期规划并执行任务,综合多因素和约束条件,并根据变化调整计划以适应新情况。此外,代理需平衡多方利益,优化结果;推理时间与日程安排;轻松导航物理环境;并利用多种工具和设备在物理世界中规划和执行操作。
个性化是代理能力的另一关键方面。它应能遵循用户的显性指令和高层软性指令,适应用户偏好和优先级的变化,基于用户目标和偏好提供建议,主动获取物理环境中的信息,并执行定时和间隔指令。代理还应具备持久记忆能力,通过情景记忆长期保留信息、回忆特定事件,以及通过长期记忆存储和检索信息。
社交智能是代理的另一核心能力。它应能捕捉人类对话中的社交线索,理解细微差别和背景,基于文化和社会线索提示用户行动,提升交流与互动效率,减少人际摩擦。此外,代理应能与安卓代理和其他数字工具交互,利用Llama等AI工具增强能力,提供已知工具和设备的使用指导,通过零样本学习适应新工具和环境,并访问庞大的工具库以支持广泛任务的指导。总体而言,可穿戴代理的能力应实现无缝且直观的支持,提升用户生产力、效率和整体体验。
5.2 架构与模型
高层次的世界建模严重依赖于设计能够推理语义明确转换的预测架构。这些模型不仅需预测未来状态,还需以支持组合性、因果性和目标导向性的方式实现。虽然生成式视觉模型可模拟像素级未来帧,但因其计算成本高且无法紧凑表示高层语义变化,故不适用于抽象推理。相比之下,在潜在空间或语言抽象空间中运行的预测模型提供了更具扩展性和通用性的替代方案。这些模型可在无需重建冗余感官细节的情况下预测行动结果,更适合高层规划任务。这推动了对大规模无标注视频语料库的自监督学习的研究,尤其是来自厨房、车间和临床环境的第一视角及教学类视频。此类视频天然包含丰富的人类活动序列,涵盖隐性目标、行动和状态转换。基于此类数据训练的高层模型应能分割并识别流程中的关键步骤,推断步骤间的潜在意图和因果关系,预测不同假设下的后续行动和可能状态,并以可解释且易于向用户传达的方式表征任务结构。
视觉-语言世界模型(VLWM)是一种基于无标注视频数据训练的预测模型,可生成交错的自然语言序列,描述行动及对应的世界状态。这些文本表征既是输出也是规划基础——可解释、可组合且可被大型语言模型处理。VLWM通过视觉上下文条件生成语言描述的未来流程,无需人工标注监督。这使得VLWM能够模拟未来轨迹、支持候选计划评估,并在符号空间中推理因果依赖关系,与人类任务理解对齐。基于VisualPlanningforAssistance(VPA)基准的实证评估显示,VLWM显著优于基于提示的基线模型,在成功率(SR)上提升+20%,平均动作准确率(mAcc)提升+10%,平均交并比(mIoU)提升+4%。通过PlannerArena进行的人类评估进一步证实,VLWM的系统-2推理模式生成的计划始终优于其他方案。
另一种值得探索的架构是基于JEPA的规划器。这些模型同样依赖高层提示(例如文本任务描述),但直接在潜在视频表征空间而非语言空间中预测结果。尽管语义透明度低于VLWM,但JEPA规划器具备两大优势:通过可微分规划目标实现梯度优化,以及在测试时的高效性(尤其与模型预测控制(MPC)结合以实现快速在线决策时)。该方法以可解释性换取性能,为资源受限或需快速适应的代理提供了互补的高层推理路径。通过系统对比VLWM与JEPA规划器,可明确语言表达性与优化驱动控制间的权衡,为具身化规划系统的设计提供指导。
5.3 基准测试
5.3.1 目标推断基准
代理式系统具有强大的潜力,但如果每次查询都需要用户提供详尽的指令,则交互负担将等同于自主完成任务。为此,第一视角多模态目标推断基准聚焦于从多模态情境观察中推断用户目标的问题。解决这一“目标推断”问题有望消除与代理交互所需的努力。本研究致力于构建强大的基准以衡量基于VLM的进展。鉴于该领域先前研究有限,研究团队收集了一个包含348名参与者、3,477段记录的新数据集,其中包含真实目标标签。下图展示了该基准中包含的多模态多样性,首次整合了视觉、音频、数字和纵向情境观察,用于推断佩戴者的目标。

人类表现优于模型,多项选择准确率达93%,而最佳VLM模型为84%。对多个现代视觉-语言模型家族的基准测试显示,更大规模的模型在任务中表现显著更优,但在生成式场景下仅55%的预测目标具有实际可用性。通过模态消融实验发现,相关模态的信息补充提升了模型表现,而无关模态的干扰影响较小。
5.3.2 WorldPrediction 基准测试
我们在第3.6.4节中详细介绍了 WorldPrediction 的底层设计。该基准测试还为可穿戴智能设备面临的特定挑战提供了实践参考。以第一视角为中心的设备必须将快速变化的第一人称视频流转化为紧凑且具有预测性的表征,从而指导设备端的辅助功能(例如,在烹饪时建议下一个工具,或在危险发生前提醒安全隐患)。由于其两项任务需要在部分可观测条件下选择高层动作和完整动作序列,WorldPrediction 映射了穿戴设备感知固有的时间抽象性和不确定性。此外,其“动作等价”设计迫使模型依赖推断出的因果结构而非像素级连续性——这正是资源受限的可穿戴设备为保持响应能力所需的抽象类型。因此,在 WorldPrediction 上评估智能体的策略生成器,可以直接衡量其是否能提前多步预测用户意图,这是开放世界环境中实现主动、情境感知辅助的前提条件。
6 第III类:机器人智能体
机器人是典型的具身化人工智能代理。它们通常配备传感器(如RGB摄像头、本体感知器、触觉传感器)以感知环境,并通过执行器与环境互动。虽然“机器人”一词涵盖了常用高级工具系统(如工业或医疗手术机器人),但我们的讨论聚焦于设计用于日常场景(如家庭或办公室)中执行通用任务且具备一定自主性的机器人。这类系统的潜力在于帮助人类完成日常事务。近期,机器人智能的进步催生了可通过人类演示(即记录人类远程操作机器人的过程)训练的系统,能够完成如折叠衣物、捡拾物品清洁房间等任务。然而,这些能力往往局限于与训练数据相似的场景。因此,我们尚未完全释放这些系统作为“额外双手”的潜力,以应对用户所需的任意任务。
6.1 能力分类法
机器人的能力大致可分为两个抽象类别:机器人的“固有”物理能力(通过硬件设计、感知、操控与移动的运动控制学习、多指手部利用、灵巧性等进步实现)以及机器人的“大脑”能力(通过推理、规划、语义理解、记忆、泛化、人类学习、人机交互及终身学习的进展实现)。尽管我们将能力分列在两类中,但并不意味着它们应完全“独立”开发。
6.1.1 物理能力
通用机器人的物理能力通常分为三类:移动、导航、(灵巧)操作。
移动与导航:二者均关注机器人从A点到B点的移动,理想情况下适用于任何地形。足式机器人在不平坦表面移动并规避路径上小型障碍物是近年来取得重大进展的难题。相比之下,导航通常涉及(隐式或显式)规划一系列动作,以达成目标(目标可能通过明确的3D坐标或视觉/文本描述指定,例如“从客厅找到并前往厨房”)。
(灵巧)操作:操作涉及对物体的有目的交互,如通用抓取与放置、高级工具使用。尽管基础抓取(及部分放置)能力已显著进步,但我们尚未见到能真正通用的“抓取-放置”智能体。灵巧操作作为重要子类,涉及对物体的精细控制(例如“将钥匙插入锁孔”“在手中调整物体方向”),通常需要或多指手的支持。该领域比粗略的抓取与放置更具挑战性,仍是开放研究问题。
尽管多数研究聚焦单一物理能力,但近期更多关注于学习“全身控制”策略,即同时控制机器人在环境中的位置及环境交互。
6.1.2 “大脑”能力
除运动控制外,通用机器人还需更高层次的智能与推理能力。
泛化能力:机器人需将知识与技能迁移至新场景。例如,人类学会在某一厨房做饭后,能在新厨房重复该任务(如搬家后)。更广泛地,我们希望机器人掌握多轴泛化:新任务与技能(动作泛化)、新实体形态、新环境与物体(视觉/语义泛化)。
高效与终身适应:即使具备最佳泛化能力,部署前也无法穷尽所有可能性。机器人需在遇到陌生场景时高效适应,且不遗忘既有技能。例如,机器人虽已学会某种叠衣方法,用户可能希望采用特定方式折叠。此类个性化应无需大量数据样本,不导致其他相关技能(如叠毛巾)遗忘,且理想情况下用户可通过直观演示(如视觉展示)完成教学。
空间与时间记忆:机器人最终需在长时间跨度下运行(可能是执行单个长期任务或多个短期任务)。因此,它需要构建空间记忆(如通过语义地图)以记录生活空间重要区域(卧室等)及物体常出现的位置,并跟踪执行任务时已完成的子任务/动作(如烹饪涉及多步骤)。最终,机器人需保留重要历史用户交互(如个性化偏好)。
语言指令与规划:机器人需在多抽象层级遵循语言指令,并将任务请求分解为更小活动单元。例如,当被要求“清理厨房”时,智能体需语义理解请求,分解子任务(“寻找脏盘子”“将脏盘子送入洗碗机”“若需要先清空洗碗机”等),并在动态环境中进行抽象任务层及具体子任务层的规划。
人机与其他智能体交互:机器人需与人类或其他机器人协作。与用户的交互包括接收指令、提问澄清、接受纠正。另一需求是机器人物理协助人类(如老年护理),或与人类(或其他机器人)协作分配任务责任。在此过程中,机器人需通过构建心理世界模型推断场景中其他智能体的意图。
6.2 架构与模型
机器人领域的技能与任务学习仍然是一个非常活跃且具有挑战性的研究方向。目前存在多种不同方法。这里我们重点选择两种截然不同的方法,用以说明世界模型所能发挥的关键作用。
近年来,基于远程操作数据训练的VLAs逐渐成为通用型机器人基础模型的有前景路径。这类模型利用VLMs将通用世界知识通过语言条件化注入策略,理论上支持开放式任务定义。目前此类方法主要聚焦于通用抓取与放置行为,目标是实现跨新环境与物体的泛化能力。高质量数据生成(干净的远程操作数据)是这一研究方向的核心,也是主要瓶颈之一。
另一种有前景的路径是通过模拟环境中的RL进行策略训练,并专注于sim2real的迁移。特别是DRL在学习人形机器人全身控制器方面已取得成功,适用于运动导航和一些灵巧操作任务。然而,目前进展仍局限于可明确定义奖励函数的任务。这一路径的主要瓶颈包括:奖励函数定义、模拟到现实的迁移(受限于场景多样性不足和模拟器中物体交互物理精度)、以及如何将RL扩展到多任务策略的语言条件化任务定义。
这两种方法本质上均假设泛化能力是数据规模(无论是远程操作数据还是模拟交互数据)的函数,并认为机器人可通过单一学习过程掌握所有所需知识。然而目前尚无法确定:我们是否能为机器人预设应对真实世界所有情况的能力?或者是否能学习到一个能在所有场景中表征所有可能技能的策略?与其追求这种理想化目标,我们更应让机器人理解其行为如何影响世界(通过学习世界模型),从而在测试阶段(推理时)自主探索新解决方案。世界模型为实现有限领域数据下的通用机器人行为提供了有前景的路径,并能自然整合多样化数据源(成功/失败的任务执行、视频数据、探索数据)。最终我们认为,结合策略模型、世界模型和"奖励"模型的系统将是实现通用机器人代理的最佳选择(见图11左图)。
6.2.1 关于解析模型的传统机器人学注释
要从世界模型中提取有效信息,需要通过推理/规划与世界模型交互,我们设想这一过程类似于模型预测控制的实现方式。基于解析世界模型的模型预测控制在机器人领域已有悠久历史,尤其适用于机器人运动的"底层"控制(示例见图11)。尽管本文讨论的是通过学习获得的动作条件化世界模型(并探讨不同动作抽象层级的世界模型),但在世界模型规划轴上无需重新发明轮子——我们可直接利用或扩展基于解析模型的机器人控制进展。
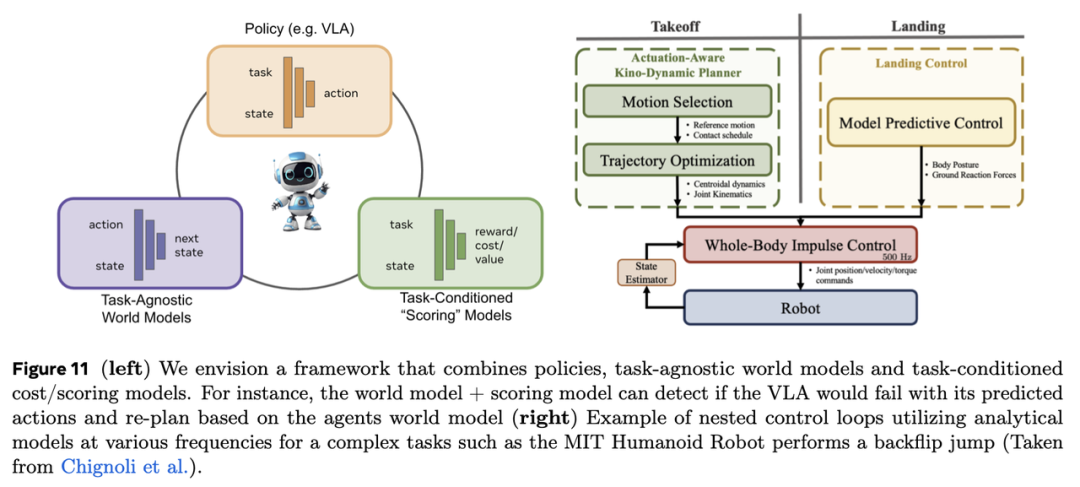
在执行低层控制任务时,如非平坦地形运动、障碍攀爬、跳跃甚至人形机器人空翻,机器人控制领域传统依赖于运动-动力学规划、模型预测控制(MPC)和机器人解析物理模型。这些模型大多未集成深度学习组件,而是通过硬编码方式表达身体与环境的动力学知识,主要依赖控制理论和不同层级的物理运动方程。以MIT人形机器人为例,其展示了在分层框架中整合不同解析控制方法实现空翻跳跃的过程(见图11)。
6.3 基准测试
机器人学的终极目标是将系统部署到真实世界。因此真实世界评估是"黄金标准"。然而真实机器人评估既耗时又难以实现可重复性。当前机器人领域主要采用三类权衡现实性、可重复性和规模的基准测试:
离线基准测试利用真实世界数据评估机器人特定能力(如识别3D场景中的物体)。这类基准测试具备可重复性和可扩展性,但无法评估模型/系统/代理在机器人上的端到端性能。
模拟基准测试基于物理引擎(如MuJoCo或pyBullet),完全可重复但通常缺乏照片级真实感,且难以精确建模机器人与物体的细粒度交互。
真实硬件评估通常在实验室环境下小规模开展,普遍不可重复,且公开的硬件评估数量极少。后续内容将聚焦基于学习方法的端到端评估。
6.3.1 仿真基准测试
仿真基准测试提供了一种可完全复现的实验环境,用于高效评估机器人agent。然而,仿真基准测试通常存在以下问题:缺乏照片级真实感,和/或无法准确建模与物体的物理交互过程(例如可变形物体如衣物的运动模拟)。这可能导致模型难以直接迁移到真实机器人上,或难以在仿真中进行模型选择,因为仿真性能是否能预测硬件性能尚不明确。对于某些能力(如视觉导航),仿真基准测试的表现与真实世界指标呈正相关,尤其是当在仿真与真实实验中均使用基于真实数据预训练的编码器(例如 VC-1)时。但对于操作类任务,目前研究发现仿真与硬件性能的相关性结论不一,这可能是因为操作任务对环境交互的依赖程度更高(相较于导航或移动任务)。
6.3.2 硬件基准测试
由于机器人评估环境的搭建与维护存在挑战,目前尚未出现大规模公共基准测试项目,用于评估通用型机器人在多样化环境中的表现。不过已有初步探索。例如“Home Robot Challenge”为研究人员提供仿真平台以原型设计和测试算法,并邀请表现优异者在真实硬件上验证算法。此外,已有研究尝试提供“硬件评估服务”,允许研究者提交策略,随后通过学习成功分类器全自动评估策略,或通过部署人类评估员对策略进行比较与排序。这些探索仍处于早期阶段,诸多问题尚待解决,例如如何在非平稳环境(机器人与环境随时间变化)中稳健提取评估指标。
实现自主学习的 AI 系统需整合被动感知与主动行为,从数据点级泛化转向任务级泛化,并通过自监督任务发现与交互驱动学习实现快速适应。
与人工系统不同,动物从出生起便通过连续、交互式且目标导向的学习过程发展能力,而非划分明确的训练阶段或固化能力。当前 AI 系统则将学习与行为割裂为不同范式(如自监督学习、强化学习),每种范式均需高度工程化的数据流水线与顺序化流程(如预训练+微调)。模型部署后,学习通常完全停止。本文认为,实现自主学习需通过架构设计将不同范式整合为可同时学习与行动的系统。
系统分类:观察学习与行动学习
可将学习算法分为两大类或范式:观察学习与行动学习,分别称为系统 A 与系统 B。系统 A 从被动感官数据中提取结构与模式,系统 B 通过目标导向的环境交互驱动学习。尽管两类范式独立发展取得了显著进展,但单独使用时均存在根本性局限。
系统 A:观察学习
系统 A 包含从原始感官输入中提取抽象表征的学习机制,涵盖静态数据集或被动采集感官流的自监督与无监督学习模型。这些范式可根据模态、数据类型与结构进一步分类:单模态(文本、图像或音频)或多模态;符号化离散数据(如 token)或连续感官输入;显式利用输入空间或时序结构的模型(如网格或时间序列)。系统 A 的优势在于:可扩展大规模数据集,发现可分层组织的抽象潜在表征(从低级感官特征到高级概念类别),并支持向下游任务迁移。但其局限性同样明显:依赖大规模精心策划的数据集或长期被动数据采集,缺乏主动选择有用数据的机制,且表征与行为能力脱节,难以在真实世界行为中落地。纯观察基础使其难以区分相关性与因果性。
系统 B:行动学习
系统 B 通过交互进行学习,最常见范式为强化学习:智能体探索环境并学习选择最大化奖励的行为。奖励来源多样,可能是任务特定的外部信号,或基于好奇心、新颖性或赋能的内部生成。动作空间的规模与结构差异显著:简单环境使用少量离散动作,而真实任务常需复杂、连续且高维动作空间。探索策略可为随机、好奇心驱动或由目标/策略引导。系统 B 的优势在于:基于控制与交互,可从稀疏或延迟结果中学习,天然适合实时与自适应行为,并能通过搜索发现创新解决方案。但其局限性包括:样本效率低下,高维或开放动作空间中的表现受限,且依赖明确指定的奖励函数与可解释动作(自然场景中常不可用)。
系统 A 辅助系统 B
系统 A 与系统 B 的整合可缓解系统 B 的多项局限。由于系统 B 在高维空间中存在样本低效性与不可行性,系统 A 可通过提供结构、先验知识与压缩表征,使学习与规划更易处理。例如,系统 A 可过滤、结构化环境或在抽象空间中模拟环境,从而降低系统 B 的负担。未来需提出一种集成架构,支持在单一系统中融合多种学习模式,例如结合大规模视频数据与少量对齐的视频-动作数据。这一方向的“北极星”可能是开发类似婴儿般学习的机器人:通过观察视频流与随机动作(motor babbling)学习有用的行动-视觉世界模型。
系统 B 辅助系统 A
系统 A 的核心局限在于依赖被动数据。缺乏指导时,可能从无信息量或无关数据流中学习。系统 B 通过主动行为可收集更优数据并为表征提供落地支撑。Gibson提出的“主动感知”经典理论——“我们为了移动而看,为了看而移动”——正是目标驱动的信息主动获取的典范。系统 B 对系统 A 的辅助可通过两种方式实现:直接优化系统 A 的预测目标,或通过探索环境生成任务相关/信息丰富的轨迹。具体形式包括:生成或选择有用数据,以及创建包含动作与感官后果配对的平行语料库。
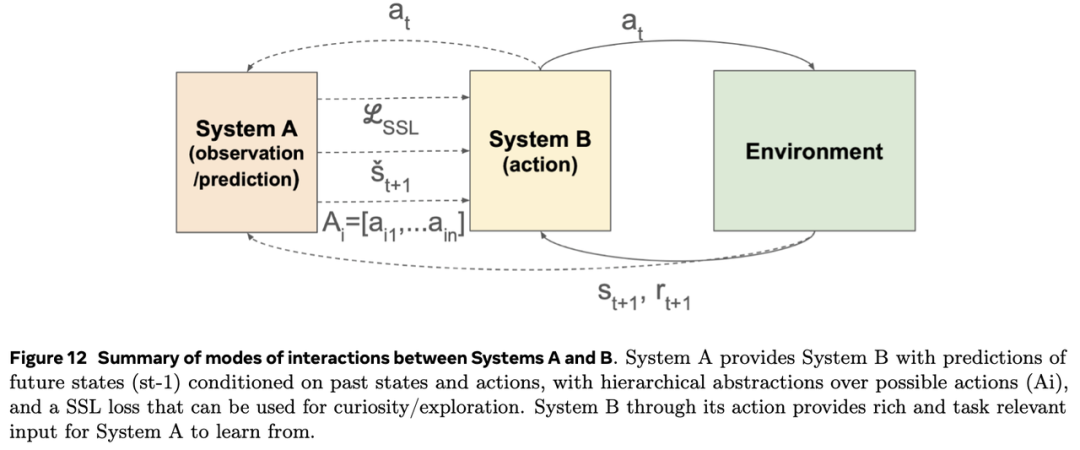
在两种情况下,系统B都通过生成并行的动作/感知数据集来丰富系统A可获得的数据,这些数据集支持跨模态学习,甚至在一定程度上实现监督学习。这是因为动作相较于嘈杂且模糊的感官输入,具有更低的方差和更高的可靠性。
简而言之,系统B有潜力通过直接从外部环境中提取数据,取代当前极其耗费资源的数据预处理和过滤步骤。当然,这假设了可以通过具身代理或大规模模拟实现规模化环境交互的可能性。
这些双向路径共同奠定了一个学习系统的基础:该系统能够协同行动与学习,即感知指导行动,行动推动感知(见图12)。
在实践中实现这一框架需要架构和训练方法的双重创新。预训练评估不仅应基于固定基准的性能,还应基于系统学习新任务的速度和效果。这需要围绕任务分布、课程学习和目标/子任务自动发现的新基准与训练范式。
SSL与RL在预训练循环中的整合,也要求对能够部署大量程序生成任务和环境的模拟器进行大规模投资。
当多个具身AI智能体协同工作时,它们可以完成单一智能体难以或无法实现的复杂任务。这种协同效应出现在多个领域:
多机器人系统 :例如在灾难救援场景中,一组机器人协作完成任务:一个机器人评估结构损坏情况,另一个搜索幸存者,第三个运送医疗物资。每个机器人凭借其独特能力为整体任务做出贡献,超越了单个机器人的能力。
自动驾驶车队 :城市中运行的自动驾驶车辆需要复杂的多智能体协作,车辆间需沟通路径、协商交叉路口通行权,并适应交通变化以确保安全高效的通行。
可穿戴设备 :用户可能同时佩戴智能眼镜、智能手表和触觉反馈背心。这些嵌入用户体内的智能体可通过协作提供更丰富、更整合的体验。例如,智能眼镜识别物体,智能手表调取相关信息,触觉背心引导用户注意力。
虚拟与增强现实环境 :在沉浸式环境中,各类具身虚拟代理(如个人助手、非玩家角色和用户控制的化身)可以开展复杂协作活动,例如建造结构或参与共享任务,相关研究已探索其在增强现实场景中的应用。
家庭辅助场景 :例如,一个具身代理家族可共同帮助人类完成晚餐筹备:一个代理规划菜单并推荐购物清单,另一个在可穿戴代理指导下完成采购和烹饪,第三个机器人协助厨房工作并在餐后清洁。
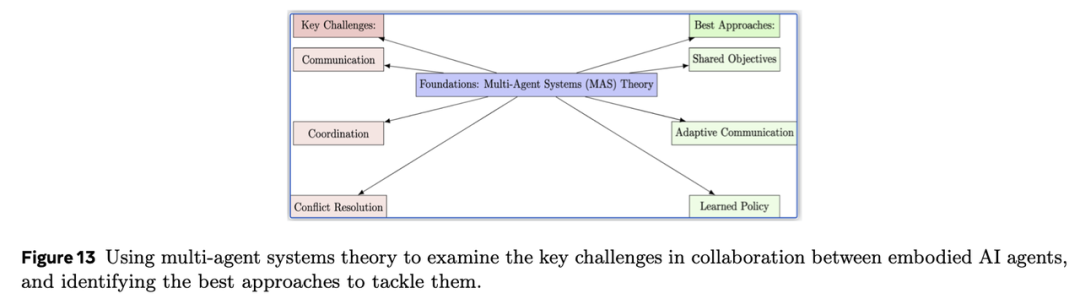
有效的多智能体协作需综合考虑通信、协调与冲突解决等核心因素。
关键挑战
在具身AI中实现无缝多智能体协作面临重大挑战:
通信 :智能体需共享信息并协调行动,这不仅涉及数据传输,更需在噪声环境、随机或不可预测条件下建立稳健且有意义的通信协议。挑战在于如何传递意图、共享感知并理解彼此信息,尤其当智能体具备不同感官能力或需自主发展通信信号时(Foerster et al., 2016)。
协调 :智能体需同步行动并克服冲突以实现共同目标。这包括去中心化控制、确保行动时机、有限资源分配,以及在仅掌握部分环境信息时的协作(Weiss, 1999)。
冲突解决 :当智能体目标或行动出现矛盾时(如个体子目标与集体目标冲突,或物理干扰),需通过协商与妥协机制实现持续协作。开发无需显式人工干预的冲突解决机制仍是一个复杂问题,通常通过混合合作-竞争环境框架探索(Lowe et al., 2017)。有效的合作基础在于机器需学会在理解和行动上找到共同基础(Dafoe et al., 2021)。
现有研究基础
多智能体系统领域提供了应对这些挑战的宝贵方法论:
分布式AI代理的通信、协调与纠纷解决基础理论;
涌现通信研究,支持智能体自主开发通信协议;
协商方法,提供超越简单冲突规则的协商框架;
多智能体强化学习进展,将深度强化学习应用于复杂合作-竞争场景;
合作型异构多机器人系统调研,揭示有效协作策略;
虚拟代理研究,为增强现实和元宇宙应用提供参考。
最佳实践
基于上述研究,可提出以下多智能体具身AI系统设计准则:
统一目标 :通过共享目标函数或奖励机制对齐智能体目标,激励合作行为;
高效通信协议 :采用预定义消息或根据环境上下文定制的高级学习通信方案;
协调机制 :小规模系统采用集中控制器,大规模部署则使用分布式算法,以同步行动并防止干扰。
最终,整合稳健的冲突解决机制对于在不可避免的分歧中维持协作至关重要。这些机制可包括协商协议、仲裁系统,或基于学习的方法——通过经验使智能体学会规避或缓解冲突。通过合理应用这些最佳实践并依托多智能体系统领域的深入研究,我们能够设计并实施日益复杂的系统,使具身AI智能体无缝协作,从而在AI能力拓展和现实应用中开辟新边界。
具身智能体的社会智能与人机交互
尽管多智能体协作聚焦于AI智能体间的交互,社会智能则强调AI智能体与人类的互动,这对具身AI系统的成功同样关键。社会智能是具身智能体的重要属性,它能使智能体以更自然有效的方式与人类互动,包括理解并解读人类行为、情绪和意图,以及生成具有情境依赖性和社会感知力的响应。
具身智能体的社会智能包含以下核心要素:
• 情绪识别 :使智能体能够识别和解读人类情绪,如面部表情、肢体语言和语调;
• 共情与理解 :使智能体能理解用户感受,并以对其情绪状态敏感的方式作出回应;
• 社会推理 :使智能体能够对社会情境和互动进行推理,包括理解社会规范、角色和关系;
• 沟通与交互 :使智能体能够通过语言和非语言线索与人类有效沟通,并开展具有情境依赖性和社会感知力的有意义互动。
9 具身AI智能体的伦理考量
当具身AI智能体在数字和物理空间中与用户互动时,可能引发重大伦理风险,威胁用户信任与福祉。两个紧迫问题是用户数据保护,以及因用户对智能体过度信任而产生的拟人化风险——这种信任可能导致用户更容易受到偏见、幻觉或虚假信息的影响。监管机构可能会优先降低这些风险,以确保具身AI智能体的安全与负责任发展。
隐私与安全
与聊天机器人或编程助手等传统AI模型不同,具身智能体深度融入我们的日常生活,实时观察、学习和适应环境。例如,嵌入可穿戴设备(如智能眼镜)的AI智能体可能监听用户对话、伴随用户移动、观看用户所见;家庭中的机器人则可能接触私人空间和日常习惯,深度理解用户行为、偏好及环境。这种具身性为记忆、学习和适应提供了前所未有的机会,但也带来隐私风险:智能体接触的数据不仅体量庞大,且涵盖从个人对话到敏感信息的广泛内容。为确保功能有效性,智能体可能需要存储部分数据(直接或通过模型权重更新间接实现),因此必须保护存储数据和模型权重。一种简单方法是将模型权重和个人数据以加密形式本地存储,防止物理访问攻击。
第二个挑战是,我们可能希望利用部分数据持续更新和改进集中式模型。技术解决方案是联邦学习 ,即数据保留在本地设备,仅传输梯度用于模型更新。但需注意,联邦学习本身无法充分保障隐私,因训练期间的梯度可能被逆向推导;可通过结合差分隐私等隐私保护技术实现隐私保护,但这可能导致准确性损失。
另一个挑战是,具身智能体是否能在日常决策中恰当识别并使用敏感数据——特别是能否在运行中实现数据最小化。近期研究表明,网络导航代理在此方面存在不足,有时会泄露完成任务非必要的敏感信息。如何防止此类行为并遵守隐私规范,是当前研究热点。负责任的开发者将优先构建兼顾性能与隐私的智能体。
拟人化风险
拟人化指将人类特征或行为归因于非人类实体,这在HCI和人工智能领域备受关注。尽管拟人化设计可增强用户体验,但也引发技术和伦理担忧。
当AI智能体被设计为模仿人类行为时,用户可能高估其能力,产生不切实际的期望。这种“幻觉代理”现象会使用户将人类意图和能力投射到AI上,进而因智能体无法完成预期任务而感到失望、沮丧甚至遭遇安全问题。拟人化设计可能掩盖AI作为机器的本质,使用户难以理解其局限性和决策逻辑,这种透明度缺失会侵蚀信任,并增加识别与纠正潜在偏见或错误的难度。为缓解此问题,设计师需采用以用户为中心的方法,优先保障透明性、自主性及对用户价值观的尊重。
具身AI智能体的拟人化行为可能影响用户现实行为。例如,若AI聊天机器人推荐特定行动或使用情感化语言,用户行为可能受其交互影响而改变。为降低风险,开发者需采取负责任且透明的AI开发方法,并可能需要教育公众如何正确与AI交互。
过度依赖拟人化设计可能导致用户对类人交互方式的依赖,这在某些场景下可能不可行或不可取。当AI无法以类人方式回应时,用户可能感到挫败或中断交互。对此,研究人员提出替代方案(如语音或手势接口)。
为缓解拟人化相关的伦理问题,我们主张采用负责任且透明的具身AI开发方法,明确传达智能体的能力与限制,并优先采用负责任的设计模式。通过正视拟人化的潜在缺陷并设计负责任的AI智能体,我们能够创造更高效、可信且以用户为中心的交互体验。
除隐私、安全和拟人化伦理挑战外,基础模型层面仍存在人类价值观对齐、模型偏见与歧视,以及幻觉问题。为应对这些挑战,Meta的研究人员正积极研究偏见缓解、幻觉缓解以及人类价值观对齐。
10 结论
对具身AI代理的探索凸显了其在虚拟、模拟、模拟拟人化技术等各个领域的变革潜力。这些代理通过整合感知与行动,提供了更自然的数字化身,提供情感智能的交互式体验。虚拟的具身AI代理,如AI虚拟形象,在治疗和娱乐等领域引发了革命,使人机交互更加自然。
具身AI代理的发展需要其能够在数字世界中无缝运作,通过感知环境、建立世界模型并进行推理规划。例如,虚拟代理需要能够学习和适应数字环境;可穿戴代理(如智能眼镜)需提升对物理世界的理解能力;机器人代理则需在非结构化环境中执行复杂任务。
同时,我们强调伦理考量的重要性,特别是在隐私/安全和拟人化方面,以确保这些技术的可持续发展。
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan
Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022.
Haneen Alsuradi, Joseph Hong, Helin Mazi, and Mohamad Eid. Neuro-motor controlled wearable augmentations:
current research and emerging trends. Frontiers in Neurorobotics, 18:1443010, 2024.
Matthieu Armando, Laurence Boissieux, Edmond Boyer, Jean-Sébastien Franco, Martin Humenberger, Christophe
Legras, Vincent Leroy, Mathieu Marsot, Julien Pansiot, Sergi Pujades, et al. 4dhumanoutfit: a multi-subject 4d dataset of human motion sequences in varying outfits exhibiting large displacements. Computer Vision and Image Understanding, 237:103836, 2023.
Mahmoud Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba Komeili, Matthew Muckley,
AmmarRizvi, ClaireRoberts, KoustuvSinha, ArtemZholus, SergioArnaud, AbhaGejji, AdaMartin, FrancoisRobert
Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil
Krishnakumar, Yong Li, Xiaodong Ma, Sarath Chandar, Franziska Meier, Yann LeCun, Michael Rabbat, and
Nicolas Ballas. V-jepa 2: Self-supervised video models enable understanding, prediction and planning, 2025.
https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/.
Pranav Atreya, Karl Pertsch, Tony Lee, Moo Jin Kim, Arhan Jain, Artur Kuramshin, Clemens Eppner, Cyrus Neary,
Edward Hu, Fabio Ramos, et al. Roboarena: Distributed real-world evaluation of generalist robot policies. arXiv
preprint arXiv:2506.18123, 2025.
Mohammad Babaeizadeh, Chelsea Finn, Dumitru Erhan, Roy H. Campbell, and Sergey Levine. Stochastic variational video prediction. In ICLR, 2018.
R. Baillargeon and S. Carey. Early childhood development and later outcome, chapter Core cognition and beyond, page 33–65. Cambridge University Press, New York, 2012.
Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng
Yu, Willy Chung, et al. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination,and interactivity. In Proceedings of the 13th International Joint Conference on Natural Language Processing and
the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long
Papers), pages 675–718, 2023.
Yejin Bang, Ziwei Ji, Alan Schelten, Anthony Hartshorn, Tara Fowler, Cheng Zhang, Nicola Cancedda, and Pascale
Fung. Hallulens: Llm hallucination benchmark. arXiv preprint arXiv:2504.17550, 2025.
Ilya Baran and Jovan Popović. Automatic rigging and animation of 3d characters. ACM Transactions on graphics
(TOG), 26(3):72–es, 2007.
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 35(8):1798–1828, 2013.
Timothy W. Bickmore and Rosalind W. Picard. Establishing and maintaining long-term human-computer relationships.ACM Trans. Comput.-Hum. Interact., 12(2):293–327, June 2005. ISSN 1073-0516. doi: 10.1145/1067860.1067867.
https://doi.org/10.1145/1067860.1067867.
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox,
Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv
preprint arXiv:2503.14734, 2025.
Florian Bordes, Quentin Garrido, Justine T Kao, Adina Williams, Michael Rabbat, and Emmanuel Dupoux. Intphys 2: Benchmarking intuitive physics understanding in complex synthetic environments. arXiv preprint arXiv:2506.09849, 2025.
Francesco Borrelli, Alberto Bemporad, and Manfred Morari. Predictive Control for Linear and Hybrid Systems.
Cambridge University Press, USA, 1st edition, 2017. ISBN 1107652871.
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding,
Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023.
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi
Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. In ICML, 2024.
Samuel Cahyawijaya, Delong Chen, Yejin Bang, Leila Khalatbari, Bryan Wilie, Ziwei Ji, Etsuko Ishii, and Pascale
Fung. High-dimension human value representation in large language models. CoRR, 2024.
Kris Cao, Angeliki Lazaridou, Marc Lanctot, Joel Z Leibo, Karl Tuyls, and Stephen Clark. Emergent communication
through negotiation. In International Conference on Learning Representations, 2018.
Longbing Cao. Ai robots and humanoid ai: Review, perspectives and directions. Perspectives and Directions (March 19, 2024), 2024.
Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Openpose: Realtime multi-person 2d pose estimation using part affinity fields. IEEE transactions on pattern analysis and machine intelligence, 43(1):172–186,2019.
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin.
Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021.
Justine Cassell. Embodied conversational agents: representation and intelligence in user interfaces. AI magazine, 22(4):67–67, 2001.
Kamalika Chaudhuri, Claire Monteleoni, and Anand D Sarwate. Differentially private empirical risk minimization.
Journal of Machine Learning Research, 12(3), 2011.
Delong Chen, Willy Chung, Yejin Bang, Ziwei Ji, and Pascale Fung. Worldprediction: A benchmark for high-level
world modeling and long-horizon procedural planning, 2025. https://arxiv.org/abs/2506.04363.
Neeraj Cherakara, Finny Varghese, Sheena Shabana, Nivan Nelson, Abhiram Karukayil, Rohith Kulothungan, Mo-
hammed Afil Farhan, Birthe Nesset, Meriam Moujahid, Tanvi Dinkar, et al. Furchat: An embodied conversational
agent using llms, combining open and closed-domain dialogue with facial expressions. In Proceedings of the 24th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 588–592, 2023.
Silvia Chiappa, Sébastien Racaniere, Daan Wierstra, and Shakir Mohamed. Recurrent environment simulators. In
ICLR, 2017.
Matthew Chignoli, Donghyun Kim, Elijah Stanger-Jones, and Sangbae Kim. The mit humanoid robot: Design, motion planning, and control for acrobatic behaviors. In 2020 IEEE-RAS 20th International Conference on Humanoid Robots (Humanoids), pages 1–8. doi: 10.1109/HUMANOIDS47582.2021.9555782.
Enrique Coronado, Takuya Kiyokawa, Gustavo A Garcia Ricardez, Ixchel G Ramirez-Alpizar, Gentiane Venture,
and Natsuki Yamanobe. Evaluating quality in human-robot interaction: A systematic search and classification of
performance and human-centered factors, measures and metrics towards an industry 5.0. Journal of Manufacturing Systems, 63:392–410, 2022.
Allan Dafoe, Yoram Bachrach, Gillian Hadfield, Eric Horvitz, Kate Larson, and Thore Graepel. Cooperative ai:
machines must learn to find common ground. Nature, 593(7857):33–36, 2021.
Remi Denton and Rob Fergus. Stochastic video generation with a learned prior. In ICML, 2018.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional
transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota, June 2019.
Association for Computational Linguistics. doi: 10.18653/v1/N19-1423. https://aclanthology.org/N19-1423/.
Xin Luna Dong. Next-generation intelligent assistants for wearable devices. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’24, page 4735, New York, NY, USA, 2024. Association for Computing Machinery. ISBN 9798400704901. doi: 10.1145/3637528.3672500. https://doi.org/10.1145/3637528.3672500.
Emmanuel Dupoux. Cognitive science in the era of artificial intelligence: A roadmap for reverse-engineering the infant language-learner. Cognition, 173:43–59, 2018.
Debidatta Dwibedi, Jonathan Tompson, Corey Lynch, and Pierre Sermanet. Learning actionable representations from visual observations. In 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 1577–1584. IEEE, 2018.
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data
analysis. In Theory of Cryptography: Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA,
March 4-7, 2006. Proceedings 3, pages 265–284. Springer, 2006.
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue, 2024. https://arxiv.org/abs/2410.00037.
Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O Stanley, and Jeff Clune. First return, then explore. Nature,590(7847):580–586, 2021.
Paul Ekman and Wallace V Friesen. Facial action coding system. Environmental Psychology & Nonverbal Behavior,
1978.
Nicholas Epley, Adam Waytz, and John T Cacioppo. On seeing human: a three-factor theory of anthropomorphism.Psychological review, 114(4):864, 2007.
Lutfi Eren Erdogan, Nicholas Lee, Sehoon Kim, Suhong Moon, Hiroki Furuta, Gopala Anumanchipalli, Kurt
Keutzer, and Amir Gholami. Plan-and-act: Improving planning of agents for long-horizon tasks. arXiv preprint
arXiv:2503.09572, 2025.
David Esiobu, Xiaoqing Tan, Saghar Hosseini, Megan Ung, Yuchen Zhang, Jude Fernandes, Jane Dwivedi-Yu, Eleonora Presani, Adina Williams, and Eric Michael Smith. Robbie: Robust bias evaluation of large generative language models. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023.
Jakob Foerster, Ioannis Alexandros Assael, Nando De Freitas, and Shimon Whiteson. Learning to communicate with deep multi-agent reinforcement learning. Advances in neural information processing systems, 29, 2016.
Aaron Foss, Chloe Evans, Sasha Mitts, Koustuv Sinha, Ammar Rizvi, and Justine T Kao. Causalvqa: A physically
grounded causal reasoning benchmark for video models. arXiv preprint arXiv:2506.09943, 2025.
Pascale Fung, Dario Bertero, Yan Wan, Anik Dey, Ricky Ho Yin Chan, Farhad Bin Siddique, Yang Yang, Chien-Sheng Wu, and Ruixi Lin. Towards empathetic human-robot interactions. In Computational Linguistics and Intelligent Text Processing: 17th International Conference, CICLing 2016, Konya, Turkey, April 3–9, 2016, Revised Selected Papers, Part II 17, pages 173–193. Springer, 2018.
Jonas Geiping, Hartmut Bauermeister, Hannah Dröge, and Michael Moeller. Inverting gradients-how easy is it to
break privacy in federated learning? Advances in neural information processing systems, 33:16937–16947, 2020.
James J Gibson. The problem of temporal order in stimulation and perception. The Journal of psychology, 62(2):
141–149, 1966.
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei,
Yunchao Yao, Xiaodi Yuan, Pengwei Xie, Zhiao Huang, Rui Chen, and Hao Su. Maniskill2: A unified benchmark
for generalizable manipulation skills. In The Eleventh International Conference on Learning Representations, 2023.https://openreview.net/forum?id=b_CQDy9vrD1.
Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Fei-Fei Li, Irfan Essa, Lu Jiang, and José Lezama.
Photorealistic video generation with diffusion models. In ECCV, 2023.
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models, 2024.
Carolina Higuera, Akash Sharma, Chaithanya Krishna Bodduluri, Taosha Fan, Patrick Lancaster, Mrinal Kalakrishnan,Michael Kaess, Byron Boots, Mike Lambeta, Tingfan Wu, and Mustafa Mukadam. Sparsh: Self-supervised touch representations for vision-based tactile sensing. 2024. https://openreview.net/forum?id=xYJn2e1uu8.
Felix Hill, Sona Mokra, Nathaniel Wong, and Tim Harley. Human instruction-following with deep reinforcement
learning via transfer-learning from text. arXiv preprint arXiv:2005.09382, 2020.
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen.
LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations,
2022.
Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li, and Tony Tung. Arch: Animatable reconstruction of clothed
humans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3093–3102,2020.
Marco Hutter, Christian Gehring, Dominic Jud, Andreas Lauber, C. Dario Bellicoso, Vassilios Tsounis, Jemin Hwangbo,Karen Bodie, Peter Fankhauser, Michael Bloesch, Remo Diethelm, Samuel Bachmann, Amir Melzer, and Mark Hoepflinger. Anymal - a highly mobile and dynamic quadrupedal robot. In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 38–44, 2016. doi: 10.1109/IROS.2016.7758092.
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail,
Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025.
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. Rlbench: The robot learning benchmark & learning environment. IEEE Robotics and Automation Letters, 2020.
Ziwei Ji, Lei Yu, Yeskendir Koishekenov, Yejin Bang, Anthony Hartshorn, Alan Schelten, Cheng Zhang, Pascale Fung,and Nicola Cancedda. Calibrating verbal uncertainty as a linear feature to reduce hallucinations. arXiv preprint arXiv:2503.14477, 2025.
Philip Nicholas Johnson-Laird. Mental models: Towards a cognitive science of language, inference, and consciousness.Number 6. Harvard University Press, 1983.
Abhishek Kadian, Joanne Truong, Aaron Gokaslan, Alexander Clegg, Erik Wijmans, Stefan Lee, Manolis Savva, Sonia Chernova, and Dhruv Batra. Sim2real predictivity: Does evaluation in simulation predict real-world performance?IEEE Robotics and Automation Letters, 5(4):6670–6677, 2020.
Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista
Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and open problems in federated learning. Foundations and trends® in machine learning, 14(1–2):1–210, 2021.
Nal Kalchbrenner, Aaron van den Oord, Karen Simonyan, Ivo Danihelka, Oriol Vinyals, Alex Graves, and Koray
Kavukcuoglu. Video pixel networks. In ICML, 2016.
Efstathios Karypidis, Ioannis Kakogeorgiou, Spyros Gidaris, and Nikos Komodakis. Dino-foresight: Looking into the future with dino. CoRR, abs/2412.11673, 2024. https://doi.org/10.48550/arXiv.2412.11673.
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan
Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. arXiv preprint
arXiv:2406.09246, 2024.
Kenneth R Koedinger and Albert T Corbett. Cognitive tutors: technology bringing learning science to the classroom.The Cambridge Handbook of the Learning Sciences, pages 61–77, 2006.
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Daniel Gordon, Yuke Zhu,
Abhinav Gupta, and Ali Farhadi. AI2-THOR: An Interactive 3D Environment for Visual AI. arXiv, 2017.
D. Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Rachel Hornung, Hartwig Adam, Hassan Akbari, Yair Alon, Vighnesh Birodkar, Yong Cheng, Ming-Chang Chiu, Josh Dillon, Irfan Essa, Agrim Gupta, Meera Hahn, Anja Hauth, David Hendon, Alonso Martinez, David C. Minnen, David A. Ross, Grant Schindler, Mikhail Sirotenko, Kihyuk Sohn, Krishna Somandepalli, Huisheng Wang, Jimmy Yan, Ming Yang, Xuan Yang, Bryan Seybold, and Lu Jiang. Videopoet: A large language model for zero-shot video generation. In ICML, 2023.
Benno Krojer, Mojtaba Komeili, Candace Ross, Quentin Garrido, Koustuv Sinha, Nicolas Ballas, and Mahmoud
Assran. A shortcut-aware video-qa benchmark for physical understanding via minimal video pairs. arXiv preprint
arXiv:2506.09987, 2025.
Vikash Kumar, Rutav Shah, Gaoyue Zhou, Vincent Moens, Vittorio Caggiano, Abhishek Gupta, and Aravind
Rajeswaran. Robohive: A unified framework for robot learning. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023.
Steven M. LaValle. Planning Algorithms. Cambridge University Press, USA, 2006. ISBN 0521862051.
Yann LeCun. A path towards autonomous machine intelligence. Open Review, Jun 2022.
Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. Federated learning: Challenges, methods, and future directions. IEEE signal processing magazine, 37(3):50–60, 2020.
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Oier Mees, Karl Pertsch, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel
Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation. In 8th Annual Conference on Robot Learning, 2024. https://openreview.net/forum?id=LZh48DTg71.
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and
Daan Wierstra. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015.
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Bench-marking knowledge transfer for lifelong robot learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko,M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 44776–44791. Curran Associates, Inc., 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/8c3c666820ea055a77726d66fc7d447f-Paper-Datasets_and_Benchmarks.pdf.
Yuxin Liu and Keng L Siau. Human-ai interaction and ai avatars. In International Conference on Human-Computer
Interaction, pages 120–130. Springer, 2023.
Stephen Lombardi, Jason Saragih, Tomas Simon, and Yaser Sheikh. Deep appearance models for face rendering. ACM Transactions on Graphics (ToG), 37(4):1–13, 2018.
Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for
mixed cooperative-competitive environments. Advances in neural information processing systems, 30, 2017.
Corey Lynch, Mohi Khansari, Ted Xiao, Vikash Kumar, Jonathan Tompson, Sergey Levine, and Pierre Sermanet.
Learning latent plans from play. In Conference on robot learning, pages 1113–1132. Pmlr, 2020.
Xiaojuan Ma, Emily Yang, and Pascale Fung. Exploring perceived emotional intelligence of personality-driven virtual agents in handling user challenges. In The World Wide Web Conference, pages 1222–1233, 2019.
Arjun Majumdar, Karmesh Yadav, Sergio Arnaud, Jason Ma, Claire Chen, Sneha Silwal, Aryan Jain, Vincent-Pierre
Berges, Tingfan Wu, Jay Vakil, et al. Where are we in the search for an artificial visual cortex for embodied intelligence? Advances in Neural Information Processing Systems, 36:655–677, 2023.
Takashi Matsuyama, Sho Nobuhara, Takaaki Takai, and Tony Tung. 3D Video and its Applications. Springer, 2012.
ISBN 978-1-4471-4119-8.
Y-Lan Boureau Matthew Le and Maximilian Nickel. Revisiting the evaluation of theory of mind through question
answering. EMNLP-IJCNLP, 2019. https://aclanthology.org/2023.findings-emnlp.717.
Maurice Merleau-Ponty. Phenomenology of Perception. Routledge, New York, 1945.
Annamaria Mesaros, Romain Serizel, Toni Heittola, Tuomas Virtanen, and Mark D. Plumbley. A decade of dcase:
Achievements, practices, evaluations and future challenges, 2024. https://arxiv.org/abs/2410.04951.
Ruaridh Mon-Williams, Gen Li, Ran Long, Wenqian Du, and Christopher G Lucas. Embodied large language models enable robots to complete complex tasks in unpredictable environments. Nature Machine Intelligence, pages 1–10,2025.
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar,
and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. In Robotics: Science and Systems, 2024.
Clifford Nass and Youngme Moon. Machines and mindlessness: Social responses to computers. Journal of social issues, 56(1):81–103, 2000.
Chuong Nguyen, Lingfan Bao, and Quan Nguyen. Continuous jumping for legged robots on stepping stones via
trajectory optimization and model predictive control. In 2022 IEEE 61st Conference on Decision and Control
(CDC), pages 93–99, 2022. doi: 10.1109/CDC51059.2022.9993259.
Quan Nguyen, Ayush Agrawal, Xingye Da, William Martin, Hartmut Geyer, Jessy Grizzle, and Koushil Sreenath.
Dynamic walking on randomly-varying discrete terrain with one-step preview. In Proceedings of Robotics: Science and Systems (RSS ’17), July 2017.
Thanh Thi Nguyen, Ngoc Duy Nguyen, and Saeid Nahavandi. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE transactions on cybernetics, 50(9):3826–3839, 2020.
Junhyuk Oh, Xiaoxiao Guo, Honglak Lee, Richard Lewis, and Satinder Singh. Action-conditional video prediction
using deep networks in atari games. In NIPS, 2015.
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv
preprint arXiv:1807.03748, 2018.
Sharon Oviatt. Multimodal interfaces. The human-computer interaction handbook, pages 439–458, 2007.
Mengxu Pan, Alexandra Kitson, Hongyu Wan, and Mirjana Prpa. Ellma-t: an embodied llm-agent for supporting
english language learning in social vr. arXiv preprint arXiv:2410.02406, 2024.
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Holsheimer, Christos Kaplanis, Alexandre
Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, Stephen Spencer, Jessica Yung, Michael Dennis, Sultan Kenjeyev,
Shangbang Long, Vlad Mnih, Harris Chan, Maxime Gazeau, Bonnie Li, Fabio Pardo, Luyu Wang, Lei Zhang,
Frederic Besse, Tim Harley, Anna Mitenkova, Jane Wang, Jeff Clune, Demis Hassabis, Raia Hadsell, Adrian
Bolton, Satinder Singh, and Tim Rocktäschel. Genie 2: A large-scale foundation world model. Blog post, 2024.
https://deepmind.google/discover/blog/genie-2-a-large-scale-foundation-world-model/.
Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised
prediction. In International conference on machine learning, pages 2778–2787. PMLR, 2017.
Georgios Pavlakos, Vasileios Choutas, Mihai Gheorghe, Federica Bogo, Catalin Ionescu, Andrea Vedaldi, and Andrew Zisserman. Smpl-x: expressive full-body 3d model of humans. arXiv preprint arXiv:1912.08804, 2019.
Mathis Pink, Qinyuan Wu, Vy Ai Vo, Javier Turek, Jianing Mu, Alexander Huth, and Mariya Toneva. Position:
Episodic memory is the missing piece for long-term LLM agents. arXiv preprint arXiv:2502.06975, 2025.
Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung-Yen Yang, Ruslan Partsey, Ruta Desai,
Alexander Clegg, Michal Hlavac, So Yeon Min, Vladimír Vondruš, Theophile Gervet, Vincent-Pierre Berges, John M Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakrishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat
Jain, Dhruv Batra, Akshara Rai, and Roozbeh Mottaghi. Habitat 3.0: A co-habitat for humans, avatars, and robots.
In The Twelfth International Conference on Learning Representations, 2024.
Rebecca Qian, Candace Ross, Jude Fernandes, Eric Michael Smith, Douwe Kiela, and Adina Williams.Perturbation augmentation for fairer nlp. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9496–9521, 2022.
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision.
In International conference on machine learning, pages 8748–8763. PmLR, 2021.
Ilija Radosavovic, Baifeng Shi, Letian Fu, Ken Goldberg, Trevor Darrell, and Jitendra Malik. Robot learning with
sensorimotor pre-training. In Conference on Robot Learning, pages 683–693. PMLR, 2023.
Sylvestre-Alvise Rebuffi, Hakan Bilen, and Andrea Vedaldi. Learning multiple visual domains with residual adapters.Advances in neural information processing systems, 30, 2017.
Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. In International conference on
machine learning, pages 1530–1538. PMLR, 2015.
Ronan Riochet, Mario Ynocente Castro, Mathieu Bernard, Adam Lerer, Rob Fergus, Véronique Izard, and Emmanuel Dupoux. Intphys 2019: A benchmark for visual intuitive physics understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(9):5016–5025, 2022. doi: 10.1109/TPAMI.2021.3083839.
Yara Rizk, Mariette Awad, and Edward W Tunstel. Cooperative heterogeneous multi-robot systems: A survey. ACM Computing Surveys (CSUR), 52(2):1–31, 2019.
Reuven Y. Rubinstein. Optimization of computer simulation models with rare events. European Journal of Operations Research, 99:89–112, 1997.
Jürgen Schmidhuber. Learning to generate sub-goals for action sequences. In Artificial neural networks, pages 967–972.Citeseer, 1991.
Melanie Sclar, Jane Yu, Maryam Fazel-Zarandi, Yulia Tsvetkov, Yonatan Bisk, Yejin Choi, and Asli Celikyilmaz.
Explore theory of mind: Program-guided adversarial data generation for theory of mind reasoning, 2024. https://arxiv.org/abs/2412.12175.
Ben Shneiderman and Catherine Plaisant. Designing the user interface: strategies for effective human-computer
interaction. Pearson Education India, 2010.
Kumar Shridhar, Koustuv Sinha, Andrew Cohen, Tianlu Wang, Ping Yu, Ramakanth Pasunuru, Mrinmaya Sachan,
Jason E Weston, and Asli Celikyilmaz. The art of llm refinement: Ask, refine, trust. In ICLR 2024 Workshop on Large Language Model (LLM) Agents, 2024.
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel
Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for
affordable and efficient robotics. arXiv preprint arXiv:2506.01844, 2025.
Kurt Shuster, Jing Xu, Mojtaba Komeili, Da Ju, Eric Michael Smith, Stephen Roller, Megan Ung, Moya Chen, Kushal
Arora, Joshua Lane, et al. Blenderbot 3: a deployed conversational agent that continually learns to responsibly
engage. arXiv preprint arXiv:2208.03188, 2022.
Franck Signe Talla, Herve Jegou, and Edouard Grave. Neutral residues: revisiting adapters for model extension. arXiv
e-prints, pages arXiv–2410, 2024.
Sneha Silwal, Karmesh Yadav, Tingfan Wu, Jay Vakil, Arjun Majumdar, Sergio Arnaud, Claire Chen, Vincent-Pierre
Berges, Dhruv Batra, Aravind Rajeswaran, Mrinal Kalakrishnan, Franziska Meier, and Oleksandr Maksymets.
What do we learn from a large-scale study of pre-trained visual representations in sim and real environments?In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 17515–17521, 2024. doi:
10.1109/ICRA57147.2024.10610218.
Linda Smith and Michael Gasser. The development of embodied cognition: Six lessons from babies. Artificial life, 11(1-2):13–29, 2005.
Vlad Sobal, Wancong Zhang, Kynghyun Cho, Randall Balestriero, Tim Rudner, and Yann Lecun. Learning from
reward-free offline data: A case for planning with latent dynamics models, 02 2025.
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. The MIT Press, second edition,http://incompleteideas.net/book/the-book-2nd.html.
Andrew Szot, Alexander Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa
Mukadam, Devendra Singh Chaplot, Oleksandr Maksymets, Aaron Gokaslan, Vladimír Vondruš, Sameer Dharur,
Franziska Meier, Wojciech Galuba, Angel Chang, Zsolt Kira, Vladlen Koltun, Jitendra Malik, Manolis Savva, and
Dhruv Batra. Habitat 2.0: Training home assistants to rearrange their habitat. In M. Ranzato, A. Beygelzimer,
Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems,
volume 34, pages 251–266. Curran Associates, Inc., 2021.https://proceedings.neurips.cc/paper_files/paper/2021/file/021bbc7ee20b71134d53e20206bd6feb-Paper.pdf.
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, Timothy Lillicrap, and Martin Riedmiller. Deepmind control suite,2018.
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas,
Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics:Bringing ai into the physical world. arXiv preprint arXiv:2503.20020, 2025.
Yuchuang Tong, Haotian Liu, and Zhengtao Zhang. Advancements in humanoid robots: A comprehensive review and future prospects. IEEE/CAA Journal of Automatica Sinica, 11(2):301–328, 2024.
Matthew Turk. Multimodal interaction: A review. Pattern Recognition Letters, 36:189–195, 2014.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable length video generation from open domain textual descriptions. In ICLR, 2023. https://openreview.net/forum?id=vOEXS39nOF.
Ethan Waisberg, Joshua Ong, Mouayad Masalkhi, Nasif Zaman, Prithul Sarker, Andrew G Lee, and Alireza Tavakkoli.Meta smart glasses—large language models and the future for assistive glasses for individuals with vision impairments.Eye, 38(6):1036–1038, 2024.
Isaac Wang, Jesse Smith, and Jaime Ruiz. Exploring virtual agents for augmented reality. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, pages 1–12, 2019.
Gerhard Weiss. Multiagent systems: a modern approach to distributed artificial intelligence. MIT press, 1999.
Genta Indra Winata, Onno Kampman, Yang Yang, Anik Dey, and Pascale Fung. Nora the empathetic psychologist. In INTERSPEECH, pages 3437–3438, 2017.
Yufan Wu, Yinghui He, Yilin Jia, Rada Mihalcea, Yulong Chen, , and Naihao Deng. Hi-tom: A benchmark for evaluating higher-order theory of mind reasoning in large language models. EMNLP Findings, 2023.https://aclanthology.org/2023.findings-emnlp.717.
Fei Xia, Amir R. Zamir, Zhi-Yang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson Env: real-world
perception for embodied agents. In Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on.IEEE, 2018.
Yufeng Yang, Desh Raj, Ju Lin, Niko Moritz, Junteng Jia, Gil Keren, Egor Lakomkin, Yiteng Huang, Jacob Donley,
Jay Mahadeokar, and Ozlem Kalinli. M-best-rq: A multi-channel speech foundation model for smart glasses,2024.https://arxiv.org/abs/2409.11494.
Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Manivasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Urtasun.Unisim: A neural closed-loop sensor simulator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1389–1399, June 2023.
Sriram Yenamandra, Arun Ramachandran, Karmesh Yadav, Austin Wang, Mukul Khanna, Theophile Gervet, Tsung-Yen Yang, Vidhi Jain, Alexander William Clegg, John Turner, et al. Homerobot: Open-vocabulary mobile
manipulation. arXiv preprint arXiv:2306.11565, 2023.
Lei Yu, Virginie Do, Karen Hambardzumyan, and Nicola Cancedda. Robust llm safeguarding via refusal feature
adversarial training. arXiv preprint arXiv:2409.20089, 2024a.
Lijun Yu, Yong Cheng, Kihyuk Sohn, José Lezama, Han Zhang, Huiwen Chang, Alexander G. Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, and Lu Jiang. Magvit: Masked generative video transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10459–10469, June 2023.
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Avnish Narayan, Hayden Shively, Adithya Bellathur, Karol
Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning, 2019.
Yaodong Yu, Maziar Sanjabi, Yi Ma, Kamalika Chaudhuri, and Chuan Guo. Vip: a differentially private foundation
model for computer vision. In Proceedings of the 41st International Conference on Machine Learning, pages 57639–57658, 2024b.
Arman Zharmagambetov, Chuan Guo, Ivan Evtimov, Maya Pavlova, Ruslan Salakhutdinov, and Kamalika Chaudhuri. Agentdam: Privacy leakage evaluation for autonomous web agents. arXiv preprint arXiv:2503.09780, 2025.
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili
Yu, et al. Lima: Less is more for alignment. Advances in Neural Information Processing Systems, 36:55006–55021,2023.
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. Dino-wm: World models on pre-trained visual features
enable zero-shot planning, 2024. https://arxiv.org/abs/2411.04983.
Zhiyuan Zhou, Pranav Atreya, You Liang Tan, Karl Pertsch, and Sergey Levine. Autoeval: Autonomous evaluation of generalist robot manipulation policies in the real world. arXiv preprint arXiv:2503.24278, 2025.
Katerina Zmolikova, Simone Merello, Kaustubh Kalgaonkar, Ju Lin, Niko Moritz, Pingchuan Ma, Ming Sun, Honglie
Chen, Antoine Saliou, Stavros Petridis, Christian Fuegen, and Michael Mandel. The chime-8 mmcsg challenge:Multi-modal conversations in smart glasses. In Proc. CHiME Workshop, 2024. https://www.isca-archive.org/chime_2024/zmolikova24_chime.pdf.
TsingtaoAI通过对前沿先进具身机器人与协作机器人的算法和智能体开发,搭建面向自动化工厂的具身智能实训平台,可以让企业在实际大规模产线决策建设前,进行预研实训,以让企业获得更快接入超级AI工厂的能力。
TsingtaoAI基于PBL的项目式实训理念,自研基于DeepSeek的具身智能实训解决方案、LLM的AIGC应用开发实训平台、基于LLM大模型的AI通识素养课数字人助手、一站式机器学习/深度学习/大模型AI训练实训平台和基于大语言模型的AIGC案例学习平台,为央国企、上市公司、外资企业、政府部门和高校提供AI&具身智能实训道场建设服务。

