
【企业内训】从训练到推理,LLM大模型技术培训-YQ集团
本培训为某汽车厂商IT团队做的LLM大模型技术内训,内容全面揭示大模型技术的核心原理与应用。深入探讨大模型从理论到实践的每一个环节,包括大模型的理论基础、关键技术如分布式并行计算、训练加速技术,以及推理优化技术。通过线上线下结合的培训模式,不仅能够掌握构建和优化大规模语言模型的方法,还将通过实际案例学习如何在不同的业务场景中应用。
培训对象:YQ集团车联网部AI团队及其他业务线相关工程师30人;
培训时长:理论培训20小时,4周伴随辅导;
赋能方式:线上和线下结合;
课程大纲
一、大模型技术原理介绍(10小时)
[通识] 大模型通识课-人工智能技术概览
[背景] 人工智能与大模型
[脉络] 语言模型技术演进
[原理] Transformer 网络
[热点] 基于Transformer网络的语言模型
[应用] 大模型提示工程及工程应用
[特性] 大模型特性及典型应用场景
[提示工程] prompt编写指导原则与技巧
[应用] 利用prompt构建对话数据(self-prompt)
[应用] prompt 与 自动化测试
[应用] prompt 与 代码生成
二、大模型训练关键技术(20小时)
[技术总览] 大模型关键技术-技术总览
[总览] 预训练语言模型学习范式
[原理] 构建大语言模型关键技术与流程
[实践] 如果构建超大规模语言模型
[并行技术] 大模型关键技术-分布式并行技术
[分布式]分布式并行计算
[集合通信]集合通信技术(MPI/NCCL)
[并行技术]并行原理(dp/tp/pp/sp/ep)
[混合并行] 混合并行与自动并行
[训练加速] 大模型关键技术-训练加速
[通信] 训练中通信优化技术(overlap)
[计算] 混合精度计算(amp)
[显存]零冗余优化器(zero1/2/3/offloading)
[显存]重计算技术(recompute)
[运行时] 算子融合技术(flashatten/fused)
[系统]系统优化(IO/网络/fen)
[训练实战] 大模型训练优化实战
[pretrain] 大模型预训练技术要点
[sft]大模型finetune训练
[adapter]大模型高效微调
[框架] 开源框架选择与案例讲解
[课堂后实践-1] llama 7b 预训练 or fine-tune (2选1)
伴随实践:(每周线上答疑1次,案例研讨1次,一共2周)
1. 如何选择基准大模型?
2. 如何评测模型指标?
3. 如何高效扩展上下文长度?
4. 如何构造finetune数据集?
5. 如何评测模型量化效果?
三、大模型推理优化技术(20小时)
[推理] 大模型推理-AI编译器和工具链
[原理] AI主流编译器及原理(TVM/MLIR/XLA)
[跨平台] 跨平台模型移植
[应用] 性能调优技术(子图优化/算子融合)
[推理] 大模型推理-推理分析优化
[原理]模型原网络结构及推理特点、推理难点
[优化技术]推理优化技术:
l 计算优化:算子融合,FlashAttention,AI 编译器(TVM)
l 显存优化:Paged Attention,int8 KV cache,int8/int4 Weights-only
l 通信优化:通信量化、通信/计算 Overlap
l 调度优化:Continious Batch 技术
l 模型压缩:量化,剪枝
l StreamLLM
[推理] 大模型推理-开源方案解析
LLM 模型推理常用开源方案:
l Fastertransformer
l TensorRT-LLM
l IMDeploy
l vLLM
l MLC-LLM
[推理] 大模型推理-优化部署案例
[模型]baichuan 网络结构介绍
[框架]部署框架优化技术解析
[部署]如何将推理引擎部署为一个服务
[评估] 效果评估
[课堂后实践-2] baichuan 7b 推理部署
伴随实践:(每周线上答疑1次,案例研讨1次)
1. 如何选择基准大模型?
2. 如何评测模型指标?
3. 如何高效扩展上下文长度?
4. 如何构造finetune数据集?
5. 如何评测模型量化效果
师资能力
➢ 大模型算法及AI引擎专家
➢ 有AI大模型实践及底层代码经验
➢ 知名互联网大厂机器学习平台算法及大模型负责人
➢ 既精通大模型训练优化技术,又拥有千亿参数大模型的完整训练实践
➢ 主流AI框架 《Deepspeed》《Megatron-LM》《ColossalAI》代码分支维护和贡献者
➢ 擅长方向:Transformer 及 MoE 模型架构优化、大模型训练及优化技术、大模型偏好对齐技术、集合通信与高性能计算、 AI混合并行训练引擎、深度学习训练及推理加 速、超大规模聚类GPU技术、大规模机器学习平台架构。
培训目标
通过培训学员具备大模型使用、训练、工程化、语音服务能力,具体目标如下:
◼ 掌握大模型理论基础知识
◼ 掌握大模型关键技术原理及技巧
◼ 掌握大模型推理优化的技术原理及开源方案
◼ 掌握工程及代码(llama 7b 混合并行预训练)案例
◼ 掌握项目及代码(baichuan 7b 推理部署)案例
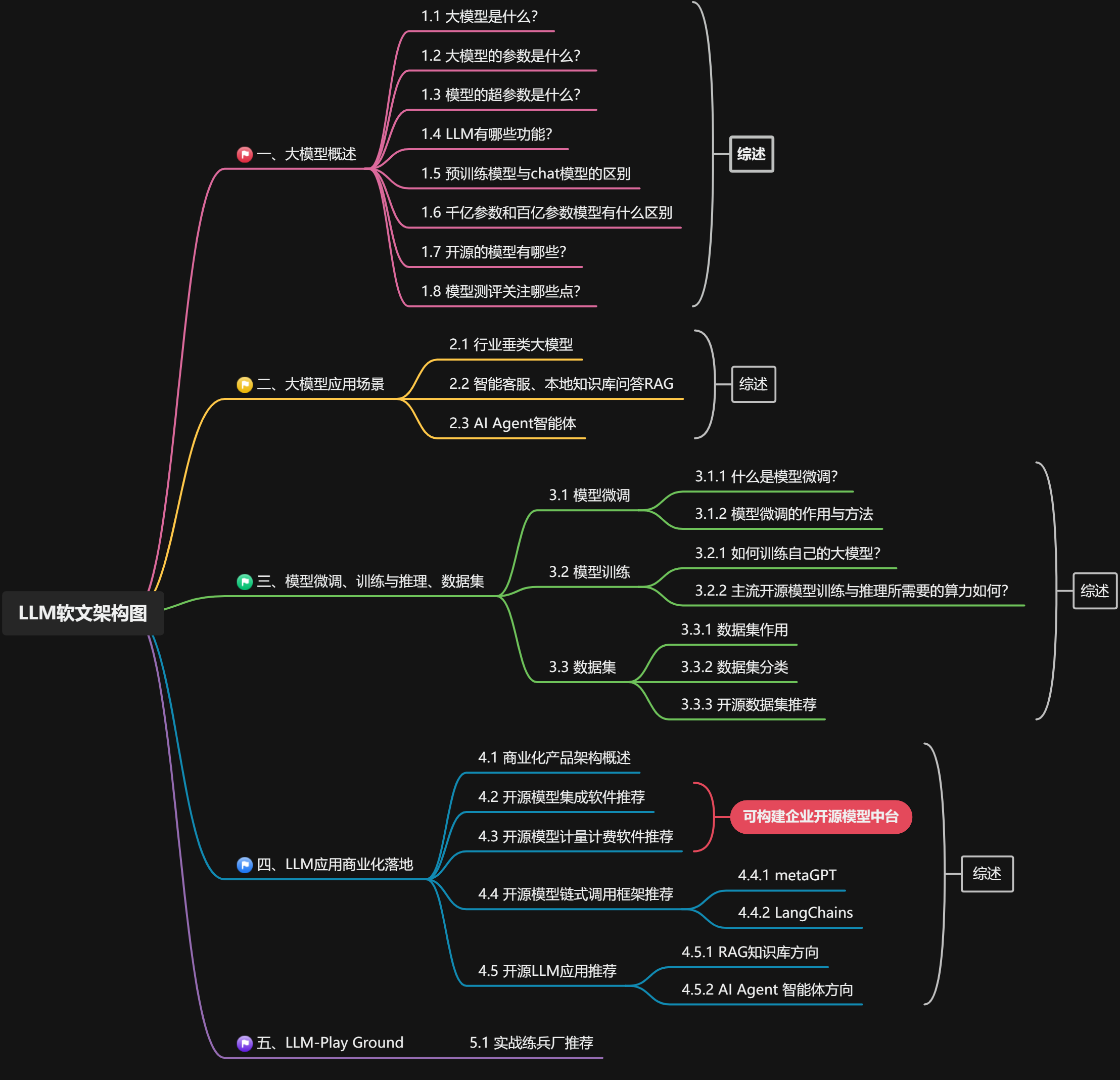
附:LLM大模型技术知识结构
附:培训现场照片


