
企业内训|DeepSeek技术革命、算力范式重构与场景落地洞察-某头部券商
3月19日北京,TsingtaoAI公司负责人汶生受邀为某证券公司管理层和投资者举办专题培训,围绕《DeepSeek技术革命、算力范式重构与场景落地洞察》主题,系统阐述了当前AI技术演进的核心趋势、算力需求的结构性变革,以及行业应用落地的关键路径。此次分享会基于DeepSeek开源大模型的技术突破与昇腾国产算力生态的实践,为从业者提供了深刻的行业洞察。
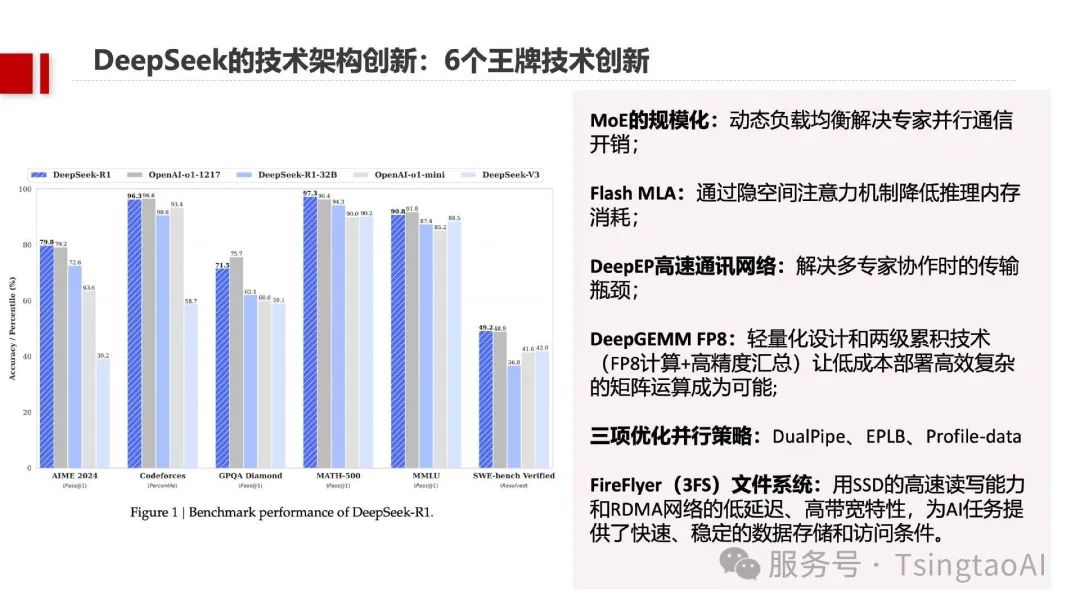
DeepSeek作为开源大模型的代表,通过多项底层技术创新,显著降低了AI训练与推理成本,重塑了技术效率天花板:
-
MoE规模化与动态负载均衡:基于256路由专家动态分配策略,稀疏激活专家模块,训练效率提升至每万亿Token仅需180K H800 GPU小时,千亿参数模型训练成本仅为Meta Llama 4的2%。
-
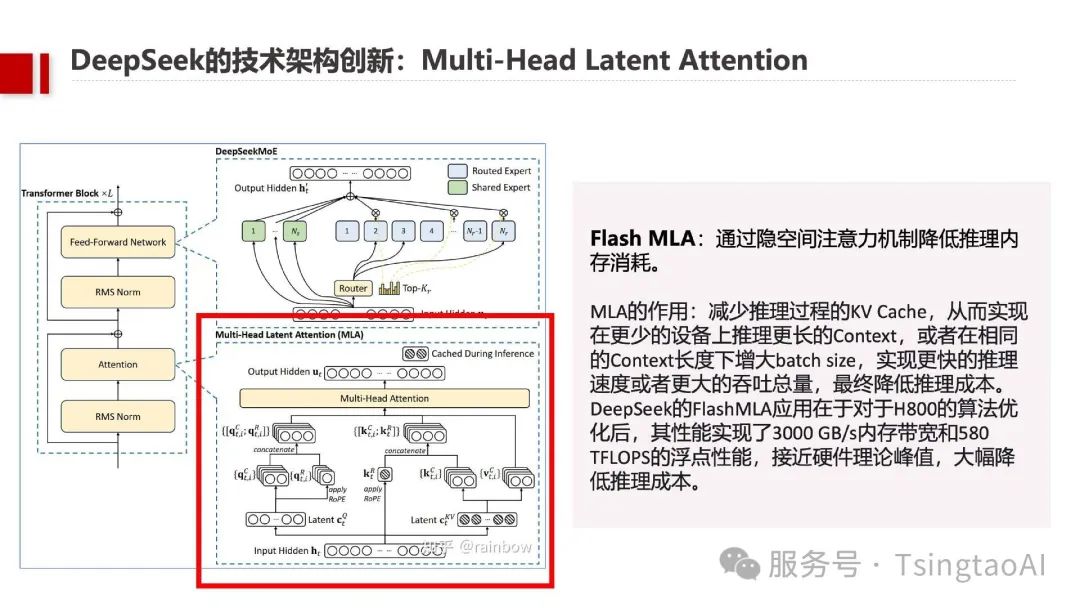
Flash MLA隐空间注意力机制:通过优化KV Cache,推理内存消耗降低30%,H800 GPU内存带宽达3000 GB/s,浮点性能接近硬件理论峰值。
-
DeepEP高速通讯网络:结合NVLink与RDMA技术,实现多专家协作时的高吞吐、低延迟,解决分布式训练中的传输瓶颈。
-
DeepGEMM极简矩阵运算库:仅300行核心代码支持非标准块大小与指令级优化,FP8计算+高精度汇总技术使边缘设备部署复杂矩阵运算成为可能。
-
三项优化并行策略:DualPipe双向流水线算法、EPLB负载均衡器与Profile-data性能剖析工具,将计算与通信效率提升40%以上。
-
Fire-Flyer高性能文件系统:在180节点集群中实现6.6TiB/s聚合读取吞吐,为AI任务提供稳定数据访问。
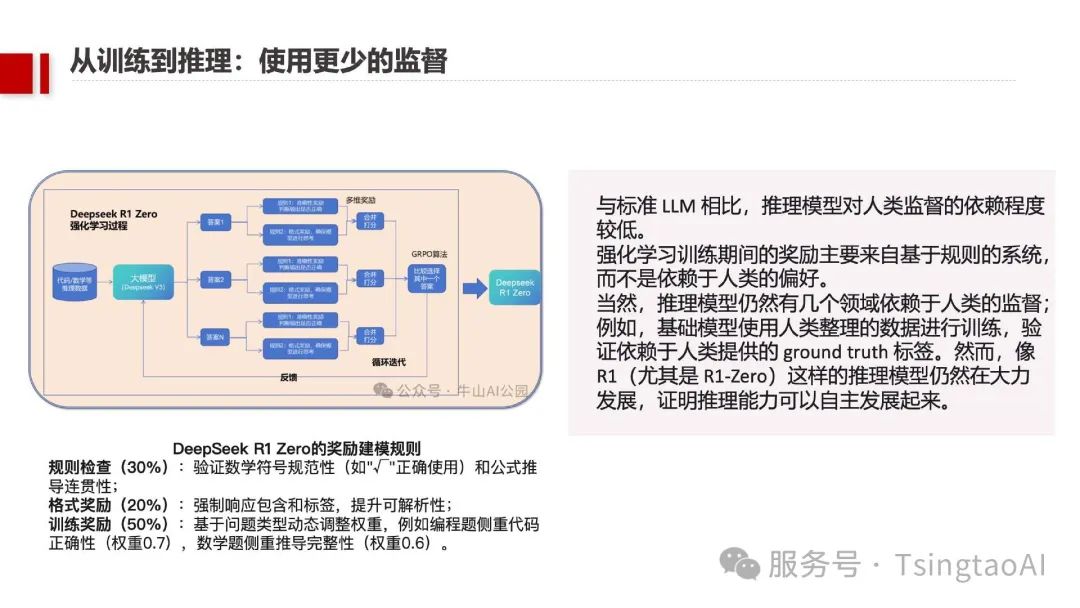
汶生强调,DeepSeek的技术架构创新不仅降低了训练成本,更通过推理端优化,推动AI从“重训练”向“重推理”的范式转移。
随着Scaling Law边际效益递减,单纯堆叠算力与参数规模已无法实现AI性能的跨越式提升。DeepSeek的技术优化与开源策略,加速了行业资源向推理端的倾斜:
-
训练瓶颈凸显:以Llama 3.1 405B模型为例,训练一次需消耗3.8×10²⁵ FLOPs,相当于3.9万张H100 GPU运行60天,高昂成本倒逼企业转向轻量化部署。
-
推理需求指数级增长:以ChatGPT月均14亿次访问为例,千亿参数模型单场景推理需2.6万张A100 GPU支持,而智能驾驶、物联网等场景对低延迟、高并发的要求进一步推升算力需求。
-
国产算力生态破局:昇腾联合DeepSeek推出“开箱即用”一体机,支持V3/R1等模型在金融、政务等场景快速落地,单机吞吐最高达7500 Token/s,并发能力提升300%。华为、浪潮等厂商的服务器订单量激增,标志着推理端算力市场进入爆发期。
汶生预测,未来3年推理算力市场规模将远超训练端,成为驱动AI芯片与服务器增长的核心引擎。
技术突破与算力重构的合力下,AI正从“技术探索”迈向“场景深耕”:
-
AI Agent成为AGI钥匙:Manus等通用Agent通过“规划-执行-验证”闭环架构、72小时长任务托管及多模型动态调度。
-
RAG取代微调成主流:面对模型快速迭代,RAG与扩展上下文组合显著降低开发门槛,企业更倾向采用云端MaaS服务而非私有化微调。
-
行业应用全面渗透:DeepSeek联合昇腾推出的一体化方案,已在北京银行、龙岗区政府、招行等40余家机构上线,覆盖智能客服、文档审核、政务咨询等场景;AI游戏引擎、低代码生成工具进一步推动UGC生态繁荣。
针对美国芯片禁运风险,汶生指出:短期看,国产芯片在性能与生态适配性上仍落后于英伟达,企业更依赖云端MaaS服务;长期看,昇腾等国产算力通过“软硬协同优化”正加速追赶。他呼吁行业关注两大趋势:
-
推理服务国产化:政务、央企等场景将优先采用国产一体机,而市场化企业则通过阿里云、火山引擎等PaaS服务平衡性能与成本。
-
技术路径转型:从“堆算力”转向算法压缩、混合精度计算,推动有限资源下的效能最大化。

关于TsingtaoAI
TsingtaoAI聚焦AI Infra、具身智能与大模型解决方案,致力于推动产教融合与校企合作,其开源技术与行业洞察已成为AI从业者的重要参考。

