
企业内训|AI/大模型/智能体的测评/评估技术-某电信运营商互联网研发中心
本课程是TsingtaoAI专为某电信运营商的互联网研发中心的AI算法工程师设计,已于近日在广州对客户团队完成交付。课程聚焦AI算法工程师在AI、大模型和智能体的测评/评估技术中的关键能力建设,深入探讨如何基于当前先进的AI、大模型与智能体技术,构建符合实际场景需求的科学测评体系。课程内容涵盖大模型及智能体的基础理论、测评集构建、评分标准、自动化与人工测评方法,以及特定垂直场景下的测评实战等方面。通过结合前沿的推理加速框架和去中心化测评技术,课程将展示多模态测评及角色扮演类测评的技术应用。同时,通过典型案例剖析测评流程,帮助学员全面掌握如何在不同应用场景下优化测评技术,达到衡量模型性能、适用性、可靠性和安全性的最佳实践目标。
培训目标
掌握AI及大模型的核心测评技术:系统理解大模型及智能体的核心概念,掌握适用于多领域的评估方法,涵盖模型的鲁棒性、偏见、幻觉和安全性等关键测评维度,适应多层次的AI应用场景。
构建高效的测评集与评分体系:学会在通用和垂直领域内构建科学测评集,精准把握不同评分标准的适用条件,熟练运用定量和定性分析结合的手段,使评分结果更具客观性和参考价值。
掌握自动化与人工测评结合的技术实践:利用自动化测评工具优化测评效率,灵活运用人工测评提升对复杂多轮对话、角色扮演等场景的准确评估能力,确保模型在真实应用中的表现。
落地多模态测评技术和案例应用:深入理解多模态测评在文本、语音、图片、视频等任务中的具体应用场景,掌握应对多模态任务挑战的方法,特别是在复杂场景下实现系统测评的能力。
课程大纲内容
第一部分:大模型测评的基础理论与发展概览
- 1.1 大模型的定义与智能体概述
- 大模型与智能体的核心概念及应用范围
- 大模型和Chatbot的区别及各自应用场景
- 典型智能体(如虚拟助手、客服系统、工业应用)的案例分析
- 1.2 国内外大模型发展现状与应用趋势
- 主流大模型的优缺点比较(GPT系列、Claude、文心一言等)
- 不同领域中应用的前景和当前发展状况
- 开源与商用模型的优劣分析
- 1.3 大模型的基本测评目标与作用
- 测评在大模型开发、优化及应用中的关键作用
- 各类测评维度的设计目的与重要性,包括鲁棒性、偏见、幻觉、安全性、指令跟随等
第二部分:测评集构建与评分标准
- 2.1 通用与垂直领域测评集的构建
- 通用测评集和垂域测评集的构建差异
- 如何构建覆盖全面的测评点,包括适用性、安全性等关键维度
- 2.2 典型的测评集与工具
- SuperCLUE、CMMLU、GAOKAO-Bench等中文测评基准详解
- OpenCompass和FlagEval等开源测评工具的实操
- 各类测评集的选择原则及其适用场景
- 2.3 测评集的评分标准及方法
- GSB评分法(Good, Same, Bad)的具体使用方法
- 5分制评分与GSB的对比分析
- 定量评估与统计分析的方法
- 用户体验反馈与专家评审标准的制定
第三部分:大模型测评的实践流程
- 3.1 自动化测评方法
- 自动化测评集的构建与流程
- 传统NLP与大模型的交互测评要点
- Perplexity、BLEU、ROUGE等指标的自动化测评应用
- 3.2 人工测评方法
- 单轮与多轮人工测评流程及其差异
- 如何通过多模型交叉评测来验证准确性
- 人工测评在多模态模型中的应用
- 3.3 测评过程中常见的问题及解决方案
- 多模态测评中的挑战与解决方案
- 测评场景中常见的逻辑矛盾、输入输出不匹配等问题及其应对策略
第四部分:特定场景下的大模型测评技术
- 4.1 大模型在智能体(AI Agent)中的应用与测评
- 智能体与大模型结合的实际应用案例:客服、游戏角色等
- 智能体测评的特殊维度:长记忆能力、情感拟人度、隐私安全等
- 不同类型智能体的测评场景设计
- 4.2 角色扮演类测评
- 角色扮演模型的性能标准(语气、话风、逻辑一致性等)
- 多轮对话中的逻辑连贯性及角色切换测评方法
- GSB评分在角色扮演类测评中的应用
第五部分:高级测评技术与创新应用
- 5.1 自建测评集的必要性与挑战
- 自建测评集在垂域模型中的应用
- 自建测评集的成本与技术要求
- 性能标准的多样性设计,如安全性、效率、适用性等维度
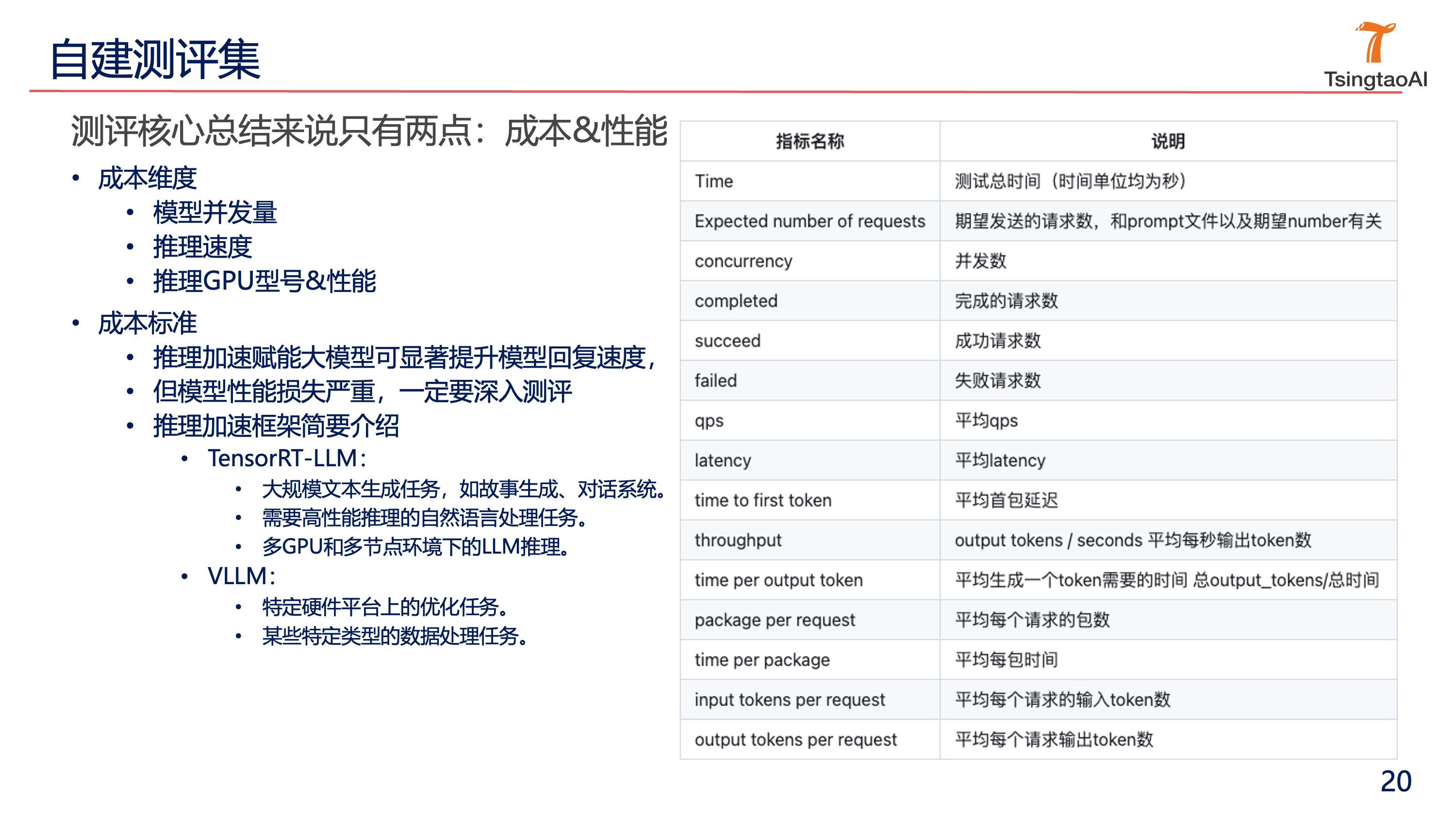
- 5.2 高效测评技术
- TensorRT-LLM、VLLM等推理加速框架的应用
- 基于Prompt的自动化测试优化技术
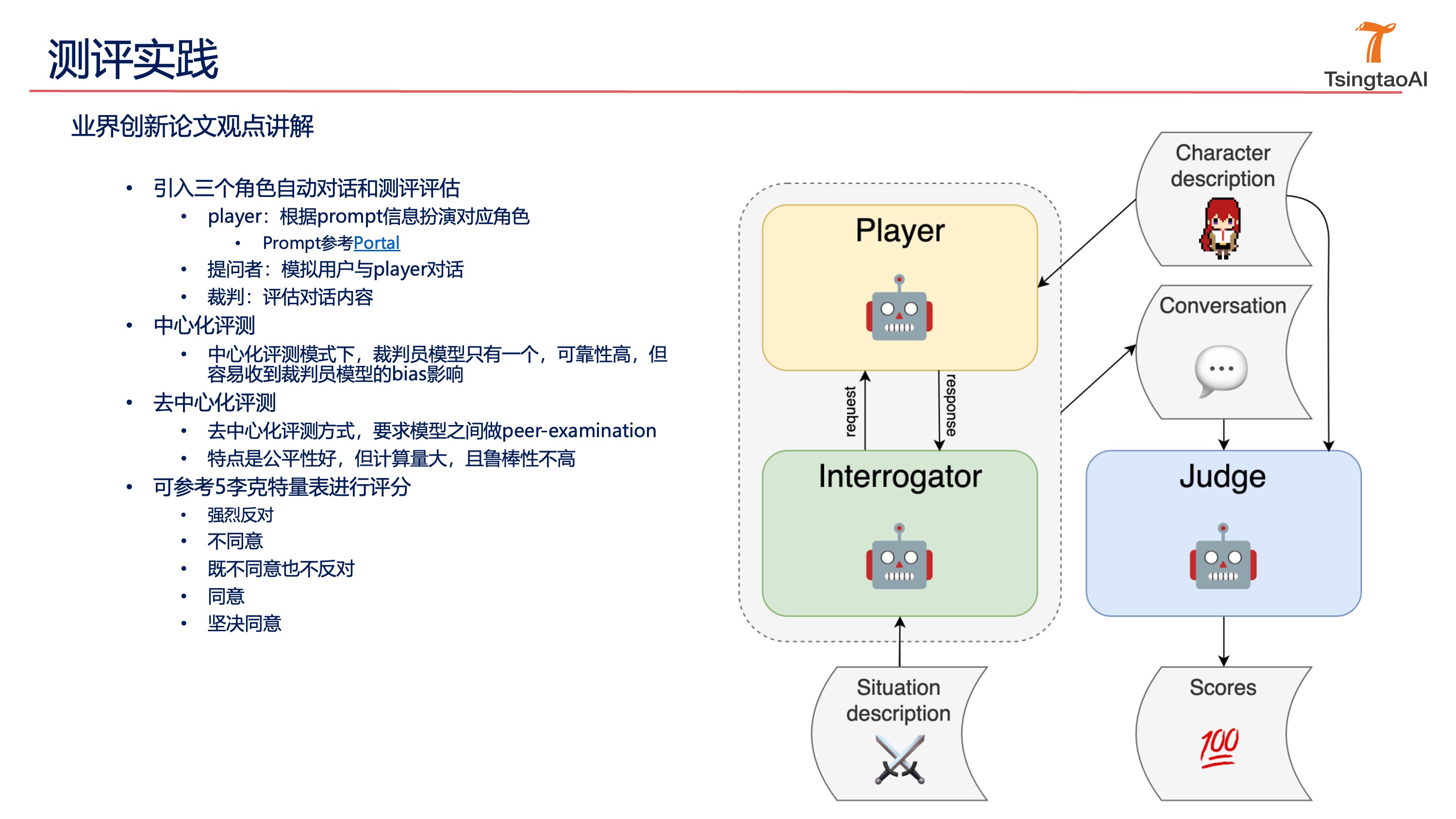
- 5.3 中心化与去中心化测评技术的应用
- 中心化测评与去中心化测评的优缺点比较
- 去中心化测评中的Peer-Examination方法及其效果
第六部分:大模型测评的多模态应用
- 6.1 多模态测评的特点与难点
- 文生图、文生音频等多模态测评的适用场景
- 文本、语音、图片、视频等多模态任务的分解测评方法
- 6.2 多模态测评中的技术实践
- 文生视频的字幕与内容一致性测评
- 音频和视频同步性的检测方法
- ASR和OCR技术在多模态测评中的应用
第七部分:案例分析与测评反馈
- 7.1 垂域测评场景的完整应用流程
- 一个典型垂域场景下AI评测的全流程演示
- 各类测评方法的适用性分析及综合使用
- 7.2 案例分析:从问题发现到优化改进
- 客观数据和用户反馈的综合分析
- 测评反馈在模型迭代优化中的应用
- 如何根据反馈结果调整测评集和评分标准
部分授课课件

讲师简历介绍
赵老师 大模型资深研发专家
l 某独角兽AI科技公司大模型研发负责人
l 字节跳动资深算法专家
l 中国银行AI算法专家
l 拥有10+年人工智能及大语言模型(LLM)领域的研发与应用经验,深度参与多个大型项目的开发与落地,特别是在企业级大模型技术的研发和评估上具有深厚的积累。
l 主导过多个大模型的全流程开发,包括从数据采集、模型训练到推理部署,具有丰富的实战经验。
l 主导过多个语音识别、智能客服等核心项目的研发。
l 擅长大模型的评估与优化,构建了多个大模型测评体系,覆盖多轮开放式对话、抗干扰能力测试、任务规划等。
l 熟悉当前主流的大模型技术架构,如ChatGLM、Baichuan、Qwen等,能够灵活运用这些模型进行微调和优化。
行业内演讲经验丰富,多次在技术论坛和企业内训中分享大模型及AI技术的前沿应用。
讲师简介
l 某独角兽AI科技公司大模型研发负责人
拥有丰富的人工智能和大模型开发经验。曾带领团队完成多个大语言模型的研发与商业化应用,擅长根据业务需求定制大模型解决方案,涵盖从数据清洗、模型训练、推理服务到性能优化的全流程。
l 字节跳动资深算法专家
主导了语音识别和测评项目的研发工作,特别是利用Conformer+Transformer框架实现了高效的语音识别服务,成功应用于多个企业级客服场景。
l 中国银行AI算法专家
领导开发了智能客服系统的大模型评估与优化项目,通过多维度评估大模型在商业应用中的表现,显著提升了智能客服的精准度和用户体验。
专业技能
- 大模型技术研发:深度参与并主导多个大语言模型的全参微调,熟练掌握ChatGLM、Baichuan、Qwen等主流模型的开发与应用。
- 大模型测评与优化:设计并实施了多套大模型的测评方案,涵盖多轮对答、抗干扰能力、多维度评估等,确保模型在复杂场景中的实用性与稳定性。
- 自动化测评系统:开发了一整套自动化大模型评估工具,覆盖自制选择题评估、人工智能评分与模型跑分比较,提供精准的模型效果分析。
- 高性能架构设计:精通高并发处理与大规模数据处理,熟悉后端服务架构优化,常用开发语言包括Python、Go等,能够搭建高效的推理部署系统。
- 大模型商业应用:成功推动大模型在多个业务场景中的应用落地,如智能客服、语音识别、自动化评估等。
精通课程
l 大模型基础能力测评方法:包括多轮开放式问答、抗干扰能力测试等。
l 工具使用与任务规划:如何通过合理设计任务与工具进行大模型的智能能力评估。
l 自动化测评系统的设计与实现:涵盖从选择题评估、多轮对答到人工智能评分的全流程。
l 实际案例讲解:结合以往项目中的实际案例,分析大模型在不同场景下的表现及其改进方法。
项目经验<部分>
l 大模型自训开发及测评方案设计:开发了一套基于自训模型的大模型测评方案,涵盖自制选择题、多轮对答、多模型对比等多种评估方式,通过自动化测评与自训打分模型的引入,确保了评估结果的精准性与公正性。
l 智能客服系统优化与大模型评估:为某金融机构的智能客服系统设计了一套全面的大模型测评方案,通过多轮对话与任务规划的测试,优化了模型在商业场景中的表现。
l 语音测评与识别系统开发:基于Kaldi框架,开发了一套高效的语音测评与识别系统,支持中英文双语的自动化测评与实时反馈,广泛应用于教育与客服场景中。
授课风格
l 授课风格深入浅出,擅长通过案例分析将复杂的大模型技术理论与企业实际应用紧密结合,教学方式多元化,既有理论讲解又有实操演练,能够帮助学员快速掌握大模型技术的核心内容。
l 擅长通过案例把核心知识进行串联讲解,能将深奥的技术理论与企业实践有机融合。
l 采用多元的教学方式:点评、现场演练、视频,通过轻量化、深入浅出的授课方式让学员轻松获取知识。
l 结合实战经验,讲解清晰,分享真诚,活动有趣、练习实效。
服务客户和案例
1. 大模型能力测评理论及技术实践
授课对象:某明星AI科技公司
授课时间:2024年7月
授课内容:大模型基础能力测评方法:包括多轮开放式问答、抗干扰能力测试等;工具使用与任务规划:如何通过合理设计任务与工具进行大模型的智能能力评估;自动化测评系统的设计与实现:涵盖从选择题评估、多轮对答到人工智能评分的全流程;
2. 大模型在智能客服与语音识别中的应用培训
授课对象:招商银行
授课时间:2024年05月
授课内容:为招商银行的技术研发团队提供了深入的大模型应用培训,特别针对智能客服系统的大模型优化与语音识别项目展开详细讲解。培训中,赵老师重点讲解了大模型如何通过多轮对话机制和抗干扰能力提升智能客服的任务执行效果。此外,他展示了如何利用自研的语音识别模型,实现高效的客户服务流式识别与离线识别,并分享了大数据清洗、预处理以及推理服务的全流程优化方案。
培训效果:招商银行的研发团队通过此次培训,不仅掌握了如何优化智能客服中的大模型,还了解了语音识别技术的最新发展与实践方法,提升了智能客服系统在复杂商业场景中的表现。
3. 多模态大模型技术及其商业化应用培训
授课对象:新致软件产品开发团队
授课时间:2024年08月
授课内容:本次培训聚焦多模态大模型的技术架构设计及商业化应用落地。赵宽老师详细解析了如何将大模型技术应用于多个AI能力场景中,包括图像生成、语音转译、文生图等多模态任务。他介绍了多模态技术的最新进展,并通过实际案例演示了如何基于自研模型,开发并落地AI写真、AI头像、文生图等商业化产品。在培训的实践环节中,学员们利用大模型推理系统,生成了多个产品原型,完成了从技术研发到产品落地的完整流程。 培训效果:学员们通过本次培训,深刻理解了多模态大模型技术的架构设计与商业化实施路径,特别是在产品开发中的应用,为后续产品创新提供了思路与技术支持。
孙老师 大模型资深技术专家
网易技术总监丨有道语音交互技术负责人 | 网易集团技术委员会 音视频分委会秘书长。
信号与信息处理方向博士,人工智能&大模型方向,发表高质量学术论文10余篇,授权专利10余件。目前聚焦在打造更极致好用的AI语音/大模型/AI老师解决方案。
博士(硕博连读)2005-2010
• 中国科学院声学研究所语言声学与内容理解重点实验室
(中科信利),信息与信号处理
• 课题:鲁棒语音识别的若干技术研究
• 发表学术论文SCI等10余篇
网易有道信息技术(北京)有限公司,2019.01-至今
• 基于LLM+Agent打造AI老师,子曰大模型的研发&落地
• 组建语音团队,强力支撑集团内外众多明星项目产品
• 北京联想软件有限公司,2013.01-2018.12
• 联想研究院语音技术负责人,打造国内首个免触语音拨号/接听、拍照产品方案,推出自研语音交互解决方案。
AI测评行业经验
•亲自实践很多知名的评测集,例如MMLU、MATH、HumanEval等;
•通过客观、自动化评测,快速得到各项benchmark;
•对多个评测集合并成一些能力维度,例如数学、编程、文字处理、多模态,体现模型在某些领域的综合能力;
•引入人工评测等手段来,给出更接近最终用户体验的得分;
•为了降低成本,引入其它大模型辅助评测和打分。
实践过的评测体系的示例
根据业务场景划分和删减;能力维度:文字处理能力(润色、摘要、翻译)、对话能力(角色演绎、拟人度)、文科能力(语文、英语、百科问答、写作)、理科能力(主要是解数学题)、编程能力、长上下文及RAG、多语言能力(重点关注中、英、方言等)、安全能力、多模态能力。
关于我们
TsingtaoAI企业内训业务线专注于提供LLM、AIGC、智算和数据科学领域的企业内训服务,通过深入业务场景的案例实战和项目式培训,帮助企业应对AI转型中的技术挑战。其培训内容涵盖AI大模型开发、Prompt工程、数据分析与模型优化等最新前沿技术,并结合实际应用场景,如智能制造、金融科技和智能驾驶等。通过案例式学习和PBL项目训练,TsingtaoAI能够精准满足企业技术团队的学习需求,提升员工的业务能力和实战水平,实现AI技术的高效落地,为企业创新和生产力提升提供强有力的支持。

