
Q3案例|AI大模型技术企业培训课程集合
|
课程名称 |
培训周期 |
培训内容及成果 |
|
RAG&CoT深度技术课程 |
2天 |
本课程深入讲解LLM领域的两大前沿技术:RAG和思维链CoT。本课程通过理论与实践相结合的方式,详细介绍RAG和CoT技术的基本原理、应用场景、技术实现方法以及最新的研究进展,帮助学员全面掌握这些技术的核心要点。 |
|
提示词工程师高阶培训 |
2天 |
本课程深入探讨深度学习与大模型技术在提示词生成与优化、客服大模型产品设计等业务场景中的应用。内容涵盖了深度学习前沿理论、大模型技术架构设计与优化、以及如何将提示词工程与智驾行业的实际业务需求紧密结合。通过深入的技术探讨、案例分析和实战操作,学员将学习到最新的LLM技术和提示词工程技巧,并掌握如何在复杂的业务环境中设计、优化和部署大模型解决方案,以提高软件系统的自动化和智能化水平。 |
|
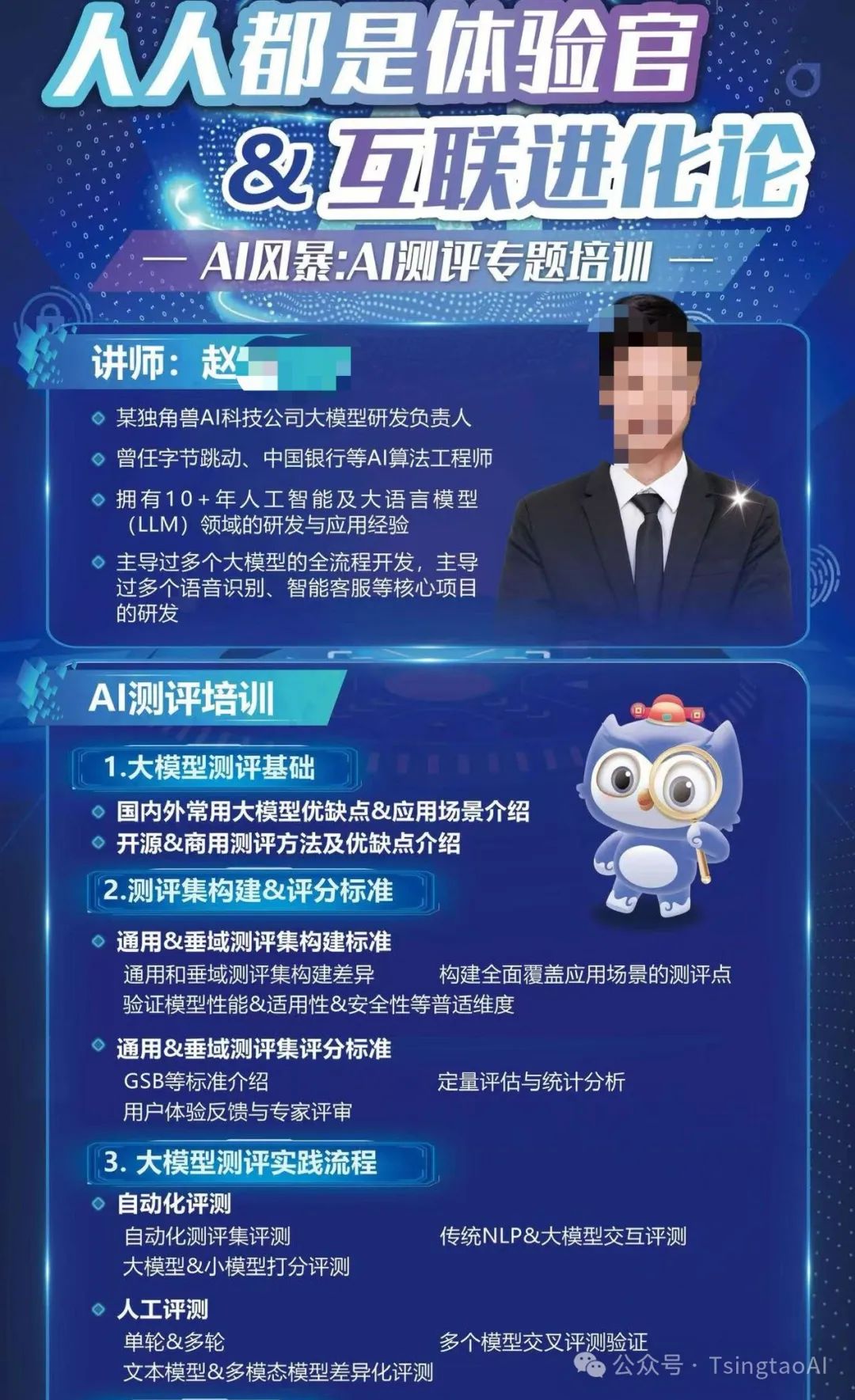
AI大模型/智能体的测评/评估技术 |
1天 |
本次培训全面解析人工智能测评的核心流程,聚焦于大语言模型及AI智能体在不同应用场景中的性能评估。内容涵盖测评集构建、自动化测评与人工测评的结合运用,尤其强调了语义理解、推理、专业能力等维度。文档指出,AI智能体的测评不仅需考量模型性能,还需关注其鲁棒性、偏见、安全性等关键指标。自建测评集被视为提升用户体验和场景适配的重要手段,能够有效弥补商用与开源测评的局限。通过结合角色扮演、语音识别等多模态测评方法,最终实现对AI模型的全面审视。 |
|
LLM大模型在服务器和IT网络运维中的应用 |
1天 |
本课程深入探讨大型语言模型在服务器及IT网络运维中的应用,结合当前技术趋势与行业需求,帮助学员掌握LLM如何为运维工作赋能。通过系统的理论讲解与实践操作,学员将了解LLM的基本知识、模型架构及其在实际运维场景中的应用,如日志分析、故障诊断、网络安全与性能优化等。 |
|
大模型训练与智能数据标注-实战技术课程 |
2天 |
课程内容涵盖了从数据采集、数据清洗、数据标注,到大模型训练和智能系统运维的全流程。通过理论讲解与实战操作相结合的方式,帮助学员掌握AI训练师所需的各项技能。课程注重大模型训练的最新技术和前沿应用,结合当前AIGC和LLM技术的发展趋势,系统地介绍了大模型在各类实际业务场景中的应用。课程内容涵盖了从数据采集与处理,到大模型训练的全流程,旨在通过详细具体的教学和实操练习,使学员能够真正掌握AI训练师所需的技能。 |
|
大模型实战技术深度研修 |
2天 |
本课程深入研修LLM大模型在实际应用中的技术实现和优化策略。通过迁移与适配、训练与调优、推理优化以及综合应用与案例分析四个模块,系统地探讨大模型的核心理论、关键技术和实践操作。课程内容涵盖模型迁移的理论与实操、预训练与微调策略、推理性能优化方法,以及大模型在工业界和学术界的实际应用案例。学员将通过实践演练,掌握如何在多模态数据集上实现模型的迁移、训练、调优和推理优化,并通过真实项目的综合实操强化对大模型技术的理解与应用。 |
一、RAG技术
1. RAG启蒙
-
定义与背景:RAG(Retrieval-Augmented Generation)的基本概念及其在自然语言处理中的重要性。
-
应用场景:RAG在信息检索、问答系统等方面的应用实例。
-
工作流介绍:RAG的基本工作流,包括查询生成、检索、重排和生成四个主要步骤。
-
具体示例:详细展示一个RAG模型从查询到生成结果的全过程。
-
环境配置:从零开始搭建RAG系统的环境配置及必要的工具安装。
-
实战步骤:逐步指导学员搭建一个简单的RAG系统,涵盖数据预处理、模型训练和结果生成。
-
提供RAG相关的代码示例和资源链接,便于学员参考和实践。
-
RAG概念入门
-
RAG工作流及示例
-
零基础搭建RAG实战
-
专栏代码地址
2. 高级RAG技术讲解
-
语义解析:深入解析Query的语义理解及其对检索效果的影响。
-
查询优化:如何通过优化Query来提高检索结果的准确性。
-
路由策略:不同Query路由策略的对比及其在实际应用中的优缺点。
-
路由实现:详细讲解Query路由的实现方法及其在RAG系统中的应用。
-
索引结构:常见索引结构(如倒排索引、哈希索引等)的原理及应用。
-
索引优化:如何通过索引优化提高检索速度和准确性。
-
检索算法:常见检索算法(如BM25、向量检索等)的原理及比较。
-
实践应用:在实际RAG系统中应用不同检索算法的案例分析。
-
重排策略:不同重排策略的介绍及其对生成结果的影响。
-
重排实现:如何在RAG系统中实现有效的重排策略,提高结果的相关性。
-
生成模型:常见生成模型(如GPT、T5等)的原理及其在RAG中的应用。
-
生成优化:如何通过优化生成模型提高结果的流畅度和准确性。
-
评估方法:RAG系统评估的常见方法及其优缺点。
-
框架介绍:主流RAG框架(如Haystack、FAISS等)的比较及使用指南。
-
RAG2.0概念:RAG2.0的新特性及其在实际应用中的优势。
-
Agent技术:如何在RAG系统中集成Agent技术,提升系统的智能化水平。
-
Query理解
-
Query路由
-
索引(Indexing)
-
Query检索
-
重排(Rerank)
-
生成(Generation)
-
评估与框架
-
RAG2.0、Agent
3. RAG实战应用
-
详细介绍RAG系统的基本工作流程,包括查询生成、检索、重排和生成等步骤。
-
通过具体案例展示Query理解在RAG系统中的重要性及其实现方法。
-
分析不同Query路由策略的应用场景及其对系统性能的影响。
-
展示索引结构在实际RAG系统中的应用,及其对检索效果的影响。
-
通过实际操作展示不同检索算法在RAG系统中的应用及效果对比。
-
RAG的基本流程
-
Query理解
-
Query路由
-
索引(Indexing)
-
Query检索
4. 高级RAG实战
-
详细介绍如何选择和配置适合RAG系统的文档解析工具,提高系统性能。
-
深入讲解如何训练和优化切分模型,提高文档切分的准确性和效率。
-
如何通过定制Embedding模型,提高RAG系统的语义理解和检索能力。
-
详细介绍LLM微调的步骤和技巧,提升生成结果的质量和相关性。
-
展示一些高级RAG技巧的实现方法,及其在实际应用中的效果。
-
高级RAG pipeline设计:如何设计和实现一个高效的RAG pipeline,提升系统性能。
-
Agentic RAG概念:Agentic RAG的基本原理及其在实际应用中的优势。
-
实践应用:展示Agentic RAG在不同应用场景中的具体实现和效果。
-
GraphRAG概念:GraphRAG的基本原理及其在实际应用中的优势。
-
实践应用:展示GraphRAG在不同应用场景中的具体实现和效果。
-
配置合适的文档解析工具
-
训练更聪明的切分模型
-
定制更强的Embedding模型
-
微调自己的LLM
-
高级RAG技巧实现& 高级RAG pipeline
-
Agentic RAG
-
GraphRAG
二、思维链CoT技术
1. 思维链技术概述
-
介绍思维链技术的基本原理和主要用途,及其在自然语言处理中的重要性。
-
回顾思维链技术的发展历程,分析其在自然语言处理中的应用及未来发展趋势。
-
基本概念
-
发展历程
2. 思维链提示方法
-
探讨如何在没有示例的情况下,通过自然语言提示引导模型进行逐步推理。
-
结合文本和图像等多模态信息,提高推理准确性和收敛速度。
-
零样本思维链提示(Zero-Shot CoT)
-
多模态思维链提示(Multimodal CoT)
3. 思维链的应用场景
-
展示模型如何在算术推理任务中使用思维链方法,提高多步数学问题的解决能力。
-
分析思维链在常识问答任务中的应用,讨论其在解决复杂常识推理问题中的表现。
-
算术推理
-
常识推理
4. 思维链技术的增强方法
-
介绍如何通过图注意力网络(GAT)增强思维链的推理能力。
-
研究如何自动生成高质量的思维链提示,提高模型在不同任务中的适用性。
-
图形思维链(Graph-of-Thought, GoT)
-
自动思维链生成(Automated CoT Generation)
5. 小模型中的思维链迁移
-
探讨如何通过指令调优(Instruction-tuning)将大模型中的思维链推理能力迁移到小模型中,以实现资源受限环境下的复杂推理。
-
模型对齐与迁移
6. 实验与案例分析
-
详细介绍在各种数据集上的实验设置,包括GSM8K和ScienceQA等数据集。
-
分析不同提示方法在多种推理任务中的表现,并提供相关实验数据与结果讨论。
-
实验设置
-
性能评估
第一模块:智能体(Agent)的应用
1.什么是智能体概要讲解
-
1.1 智能体的定义与特点
-
1.2 智能体的分类(自主智能体、交互智能体、协作智能体等)
-
1.3 智能体的基本结构(感知、决策、行动)
2.设计智能体的因素与过程
-
2.1 构建智能体的基本要素(感知器、效应器、学习算法等)
-
2.2 智能体的设计流程(需求分析、模型选择、算法实现)
-
2.3 环境对智能体构建的影响(封闭环境与开放环境)
-
2.4 智能体的测试与验证
3.索引技术在智能体的作用
-
任务规划与记忆管理
-
长短时记忆协作
-
多任务并行执行
-
信息检索与优化
4.企业构建智能体的落地场景种类
-
4.1 构建知识库型智能体(Knowledge-Based Agents)
-
4.2 构建系统集成型智能体(ERP-Integrated Agents)
-
4.3 构建决策类智能体(Decision-Making Agents)
-
4.4 构建行动类智能体(Action-Oriented Agents)
-
关键点回顾(技术)
-
信息检索、知识图谱构建
-
API集成、中台系统、微服务架构
-
机器学习(ML)、深度学习(DL)、数据分析与预测
-
机器人流程自动化(RPA)、物联网(IoT)、自动化控制
5.强化学习在智能体的应用
-
5.1 强化学习的基本原理与框架
-
5.2 强化学习在智能体中的实际应用(机器人控制、游戏AI等)
-
5.3 强化学习的挑战与优化(探索与利用的平衡、奖励设计)
6.综合应用与讨论
LLM Chain与ReAct Agent切换:实现对话与规划功能的融合。
双记忆机制:长时记忆与对话连贯。
ReAct能力:集成了规划与执行的循环反馈系统。
案例分享
基于llama大模型的数字人智能体的构建。agent 主要功能涉及如下:
-
自主决策能力
-
任务管理与自动化
-
高度的可定制性与模块化设计
-
增强的互动功能
第二模块:开源大模型的应用与部署,微调
1.深入探讨LLaMA3的指标和参数
-
1.1 LLaMA3的性能指标(准确率、推理速度、参数量等)
-
1.2 LLaMA3模型的核心架构
-
1.3 对比其他开源模型的优势与劣势
2.LLaMA3的数据分布情况
-
2.1 LLaMA3的训练数据源(公开数据、特定领域数据等)
-
2.2 数据预处理与清洗的策略
-
2.3 数据分布对模型表现的影响(领域特化、泛化能力等)
3.LLaMA3的微调技术
-
3.1 微调的概念与必要性
-
3.2 微调的不同方法(全模型微调、部分参数微调、LoRA等)
-
3.3 迁移学习作为微调策略
-
3.4 微调过程中的常见挑战(过拟合、数据不足等)
4.LLaMA3部署流程,资源评估
-
4.1 部署前的硬件资源评估(GPU/TPU要求、内存需求等)
-
4.2 LLaMA3模型的部署步骤(环境准备、模型加载、接口设计)
-
4.3 部署中的成本优化建议(集群配置、弹性扩展等)
5.模型与国产适配
-
5.1 LLaMA3与国产芯片(如昇腾)的适配方案
-
5.2 国产大模型的竞争与合作
-
5.3 模型适配中的性能优化措施
6.推理与优化
-
6.1 推理速度优化的技术(模型剪枝、量化、蒸馏等)
-
6.2 推理在不同场景中的表现分析(实时性要求、批处理应用等)
-
6.3 推理服务的高可用性和容错机制
7.垂直领域的小模型应用
-
7.1 垂直领域小模型的定义与优势
-
7.2 小模型在特定行业的部署(法律、医疗、金融等)
-
7.3 小模型在资源受限场景下的应用(低功耗设备、边缘计算等)
案例分享
基于llama3的 助教项目的案例分享,涉及以下技术:
-
llama3的在教学方向的微调
-
llam3的部署,资源的评估方式
-
国产的适配
-
如果通过推理和优化,提升处理能力等。
第三模块:提示词的优化
以智能客服系统为案例,重点讲述提示词的优化过程、方向和效果。以及优化过程的改进方法、数据分析和迭代的过程。
1.提示词优化的方向概要
-
1.1 提示词在大模型中的作用
-
1.2 提示词优化的主要方向(语言精确性、上下文连贯性、响应速度等)
-
1.3 提示词优化对模型表现的提升(生成内容的相关性与准确性)
2.基于客服系统的提示词优化全流程
-
2.1 客服系统提示词优化的需求分析(高效响应、个性化服务等)
-
2.2 提示词设计的初期迭代(关键词提取、用户行为分析)
-
2.3 提示词优化的反馈与改进(根据用户反馈不断调整)
3.基于客服系统提示词优化的总结
-
3.1 常见提示词优化问题与解决方案
-
3.2 提示词优化的长期维护(动态更新、定期评估)
-
3.3 提示词优化的成功案例分析
全部课程的回顾
回答问题和讨论
第一部分:大模型测评的基础理论与发展概览
-
大模型与智能体的核心概念及应用范围
-
大模型和Chatbot的区别及各自应用场景
-
典型智能体(如虚拟助手、客服系统、工业应用)的案例分析
-
主流大模型的优缺点比较(GPT系列、Claude、文心一言等)
-
不同领域中应用的前景和当前发展状况
-
开源与商用模型的优劣分析
-
测评在大模型开发、优化及应用中的关键作用
-
各类测评维度的设计目的与重要性,包括鲁棒性、偏见、幻觉、安全性、指令跟随等
-
1.1 大模型的定义与智能体概述
-
1.2 国内外大模型发展现状与应用趋势
-
1.3 大模型的基本测评目标与作用
第二部分:测评集构建与评分标准
-
通用测评集和垂域测评集的构建差异
-
如何构建覆盖全面的测评点,包括适用性、安全性等关键维度
-
SuperCLUE、CMMLU、GAOKAO-Bench等中文测评基准详解
-
OpenCompass和FlagEval等开源测评工具的实操
-
各类测评集的选择原则及其适用场景
-
GSB评分法(Good, Same, Bad)的具体使用方法
-
5分制评分与GSB的对比分析
-
定量评估与统计分析的方法
-
用户体验反馈与专家评审标准的制定
-
2.1 通用与垂直领域测评集的构建
-
2.2 典型的测评集与工具
-
2.3 测评集的评分标准及方法
第三部分:大模型测评的实践流程
-
自动化测评集的构建与流程
-
传统NLP与大模型的交互测评要点
-
Perplexity、BLEU、ROUGE等指标的自动化测评应用
-
单轮与多轮人工测评流程及其差异
-
如何通过多模型交叉评测来验证准确性
-
人工测评在多模态模型中的应用
-
多模态测评中的挑战与解决方案
-
测评场景中常见的逻辑矛盾、输入输出不匹配等问题及其应对策略
-
3.1 自动化测评方法
-
3.2 人工测评方法
-
3.3 测评过程中常见的问题及解决方案
第四部分:特定场景下的大模型测评技术
-
智能体与大模型结合的实际应用案例:客服、游戏角色等
-
智能体测评的特殊维度:长记忆能力、情感拟人度、隐私安全等
-
不同类型智能体的测评场景设计
-
角色扮演模型的性能标准(语气、话风、逻辑一致性等)
-
多轮对话中的逻辑连贯性及角色切换测评方法
-
GSB评分在角色扮演类测评中的应用
-
4.1 大模型在智能体(AI Agent)中的应用与测评
-
4.2 角色扮演类测评
第五部分:高级测评技术与创新应用
-
自建测评集在垂域模型中的应用
-
自建测评集的成本与技术要求
-
性能标准的多样性设计,如安全性、效率、适用性等维度
-
TensorRT-LLM、VLLM等推理加速框架的应用
-
基于Prompt的自动化测试优化技术
-
中心化测评与去中心化测评的优缺点比较
-
去中心化测评中的Peer-Examination方法及其效果
-
5.1 自建测评集的必要性与挑战
-
5.2 高效测评技术
-
5.3 中心化与去中心化测评技术的应用
第六部分:大模型测评的多模态应用
-
文生图、文生音频等多模态测评的适用场景
-
文本、语音、图片、视频等多模态任务的分解测评方法
-
文生视频的字幕与内容一致性测评
-
音频和视频同步性的检测方法
-
ASR和OCR技术在多模态测评中的应用
-
6.1 多模态测评的特点与难点
-
6.2 多模态测评中的技术实践
第七部分:案例分析与测评反馈
-
一个典型垂域场景下AI评测的全流程演示
-
各类测评方法的适用性分析及综合使用
-
客观数据和用户反馈的综合分析
-
测评反馈在模型迭代优化中的应用
-
如何根据反馈结果调整测评集和评分标准
-
7.1 垂域测评场景的完整应用流程
-
7.2 案例分析:从问题发现到优化改进
第一部分:LLM基础与模型部署
-
1.1 LLM的架构与工作原理
-
1.2 主流LLM及其特点(如GPT、BERT等)
-
2.1 小模型的选择与使用场景
-
2.2 模型部署的技术栈与工具
-
3.1 数据收集与管理的最佳实践
-
3.2 运维数据的分类与标注
-
3.3 构建高质量的训练数据集
-
大型语言模型基础
-
小模型的部署
-
运维数据整理
第二部分:LLM在运维中的应用
-
故障模式识别与分析
-
生成故障诊断报告
-
4.1 日志分析的必要性与挑战
-
4.2 LLM在日志分析中的应用
-
通过历史数据分析生成预测模型
-
实时监控与告警系统集成
-
根据故障模式生成维护计划
-
经验知识库的构建与利用
-
5.1 LLM在故障预测中的应用
-
5.2 预防性维护建议生成
-
利用LLM自动识别恶意流量特征
-
实时监控与响应机制的设计
-
LLM在安全事件识别中的应用
-
自动生成安全事件报告与响应措施
-
6.1 恶意流量检测
-
6.2 安全日志分析
-
日志分析与故障诊断
-
故障诊断与预防性维护
-
网络安全中的LLM应用
第三部分:性能优化与自动化运维
1. 性能优化
-
LLM在性能分析中的角色
-
生成性能瓶颈识别报告
-
7.1 性能瓶颈分析
-
7.2 资源调度优化:基于LLM生成最优资源调度方案
2. 自动化运维
-
利用LLM生成常见运维脚本
-
自适应脚本的设计与实施
-
生成运维文档的标准化流程
-
文档内容的自动更新与管理
-
8.1 自动化脚本生成
-
8.2 自动化文档生成
第一部分:行业数据采集与处理
1. 数据采集基础与业务场景分析
-
数据采集在大模型训练中的作用及其对模型效果的影响
-
行业内常见的数据采集场景及对应的采集需求
-
数据采集工具介绍:Scrapy、BeautifulSoup、Selenium的基础应用
-
自动化与手动数据采集的权衡与选择
2. 业务数据采集实操
-
Scrapy、BeautifulSoup、Selenium的高级应用与实操演示
-
实时数据采集与批量采集的策略和工具选择
-
业务场景中的数据获取:案例分析与实践
3. 数据清洗与整理
-
数据清洗的重要性:如何保证数据的质量
-
数据清洗常见问题及其解决方案:缺失值、重复数据、噪音数据处理
-
Pandas等工具在数据清洗中的实操演示
-
数据整理与归类:如何提高后续标注和训练的效率
4. 数据增强与合成数据的使用
-
数据增强技术:提升数据多样性的方法(随机裁剪、翻转、旋转等)
-
合成数据在数据稀缺场景中的应用与实践
第二部分:智能数据标注与质量控制
5. 数据标注的基础概念与行业应用
-
数据标注在大模型训练中的重要性及其对模型效果的影响
-
人工标注与自动标注的优缺点分析
-
各类数据标注工具的介绍:Amazon SageMaker Ground Truth、CVAT、PaddleX等
-
行业特定数据的标注要求与技术挑战
6. 文本/视觉/语言数据标注实操
-
文本数据标注:NLP数据集的构建与标注技术(Hugging Face应用)
-
视觉数据标注:YOLO与EfficientDet在图像检测与标注中的应用
-
语言数据标注:如何有效处理对话数据与语音数据
7. 数据标注质量控制与优化
-
如何评估和提高数据标注的准确性与一致性
-
数据标注的审核流程与问题纠正
-
标注数据的自动化审核与修正工具介绍
8. 标注数据的分类与统计实操
-
数据分类的基础方法与工具选择
-
数据统计与可视化工具的应用(如Tableau、Quick BI)
-
业务场景下的标注数据统计分析与报告撰写
第三部分:大模型训练与优化
9. 大模型的定义、架构与应用场景
-
大模型的基本概念与行业发展趋势
-
GPT-4、EfficientDet、YOLO等典型大模型架构解析
-
特定行业中的大模型应用案例分析:如金融、医疗、制造业等
10. 模型训练的核心流程与工具
-
数据准备与分布:如何确保训练数据的质量与多样性
-
PyTorch与TensorFlow框架的使用技巧与实操演示
-
常见模型训练问题解析:过拟合、欠拟合与数据不平衡问题
11. 模型训练实战
-
基于实际业务场景的大模型训练案例分析与实操演练
-
模型训练中的超参数调优策略与技巧
-
使用分布式训练加速大模型的训练过程
12. 模型评估与调优策略
-
模型评估指标的选择:准确率、召回率、F1分数等
-
模型调优的常见方法:交叉验证、超参数优化、梯度下降等
-
模型优化案例分享:如何通过调参提升模型性能
13. 对话系统的模型训练与优化
-
对话系统的基本原理与训练方法
-
利用预训练模型构建行业特定的智能对话系统
-
对话数据的标注与训练技巧
14. SFT与专项训练实操
-
SFT训练的实际应用与专项能力模型的构建
-
如何根据业务需求构造专项数据并进行模型训练
-
BADCASE处理与模型优化策略的实操演示
第四部分:模型部署与业务应用
15. 大模型的评估与部署流程
-
模型部署的常见挑战与解决方案
-
如何根据业务需求进行模型裁剪与优化部署
-
大模型的持续学习与在线训练
16. 业务场景中的大模型应用实战
-
行业定制化大模型的应用案例分析与实践
-
如何将大模型应用于实际业务场景中
-
大模型的性能监控与持续优化方法
第一部分:大模型的迁移与适配
1.1 课程导入与目标介绍
-
课程简介与学习目标。
-
大模型在当前技术环境下的重要性。
-
课程涉及的主要工具和框架概述。
1.2 模型迁移与适配概述
-
模型迁移的理论基础。
-
多模态大模型的定义与应用场景。
-
迁移学习的技术原理与实践意义。
-
相关前沿论文与技术趋势解析。
1.3 多模态大模型迁移的实操演练
-
如何选择适合的预训练模型进行迁移。
-
模型的微调与适配,涵盖参数调整与数据集扩展。
-
实操:从图像识别到文本生成的跨模态迁移。
-
实操:不同场景下的模型适配与迁移策略。
-
演练环境准备:基于多模态数据集的构建与预处理。
-
迁移演练:
1.4 问题讨论与疑难解答
-
学员针对迁移过程中遇到的问题进行讨论。
-
讲师总结迁移中的关键要点与常见问题的解决方案。
第二部分:大模型训练与调优
2.1 训练与调优基础概念回顾
-
预训练与微调的区别与联系。
-
大模型的预训练过程概述。
-
参数调优的重要性与常见策略。
2.2 大模型预训练与持续预训练的深入讲解
-
数据集的选择与准备。
-
预训练模型架构的选择与修改。
-
多GPU/TPU环境下的大规模预训练策略。
-
实操:构建与运行预训练任务。
-
增量数据对模型性能的影响。
-
持续预训练的场景与方法。
-
实操:基于增量数据的持续预训练演练。
-
预训练过程分析:
-
持续预训练:
2.3 SFT与DPO的实操演练
-
SFT的原理与应用场景。
-
实操:如何通过SFT提升模型的特定任务性能。
-
实操:数据标签化与SFT流程的优化。
-
DPO的基本概念与理论基础。
-
实操:通过DPO实现对模型输出的偏好调整。
-
实操:DPO在多模态模型中的应用案例。
-
SFT的理论与实践:
-
DPO的理论与实践:
2.4 训练与调优过程中的常见问题与解决方案
-
模型过拟合与欠拟合问题的识别与应对。
-
学习率的调整与优化策略。
-
参数调优中的常见陷阱与规避方法。
第三部分:大模型推理优化
3.1 推理优化的基础理论与实践意义
-
推理过程的概述与常见挑战。
-
模型推理的性能瓶颈分析。
-
多机多卡分布式推理的必要性与优势。
3.2 llama3.1 405B模型的分布式推理实操
-
分布式推理所需的硬件与软件环境搭建。
-
基于NCCL和Horovod的分布式推理框架。
-
分布式推理流程解析与实操。
-
通过多机多卡进行推理的性能分析与优化。
-
实操:在特定任务下的llama3.1 405B模型分布式推理。
-
性能调优与推理时间的压缩策略。
-
推理环境配置:
-
推理演练:
3.3 基于MindIE的大模型推理实操
-
MindIE架构与工作原理。
-
多模态推理的挑战与解决方案。
-
实操:配置并运行基于MindIE的多模态模型推理任务。
-
实操:优化推理性能,减少资源占用。
-
MindIE简介与多模态推理:
3.4 推理优化的前沿技术与研究
-
推理效率提升的最新技术趋势。
-
相关前沿论文的深度解读。
-
性能调优的创新方法与工具。
第四部分:综合应用与案例分析
4.1 综合应用案例介绍与分析
-
典型大模型应用场景介绍。
-
成功案例分析:大模型在工业界与学术界的应用。
-
大模型的部署与运维挑战。
4.2 真实项目的实操演练
-
结合学习内容,选择一个真实项目进行综合实操。
-
项目目标设定与工作流程规划。
-
数据准备与预处理。
-
模型训练与调优。
-
模型推理与性能优化。
-
项目展示与结果分析。
-
项目选题与规划:
-
实操演练:
4.3 总结与展望
-
课程回顾与知识点总结。
-
学员展示项目成果与经验分享。
-
未来技术趋势展望与技能提升路径建议。
-
答疑解惑与课程反馈。
北京邮电大学,网络与交换国家重点实验室,计算机科学与技术硕士。某互联网大厂高级工程师,深度学习框架开发与性能调优专家horovod,spark,iceberg,hudi 等系列源码贡献者,“Tim 在路上”公众号主理人。
专业能力
熟悉深度学习框架,模型性能调优,有过深度学习框架开发调优经验。
熟悉 GPU, NPU, CUDA, CANN, Nccl, IB 等底层原理与工程实践。
熟悉数据湖/数据引擎的开发优化,例如针对SparkSQL 源码级优化开发。
达观数据副总裁,高级工程师,浦东新区"明珠计划"菁英人才、BroadView2023“技术成长领路人”,人工智能标准编制专家。曾获得广东省科技进步奖二等奖,上海市计算机学会科技进步奖二等奖和上海市浦东新区科技进步奖二等奖。人工智能标准编制专家,《知识图谱:认知智能理论与实战》作者,参与编撰《智能文本处理实战》,《新程序员 * 人工智能新十年》顾问专家和文章作者,专注于知识图谱、通用人工智能 AGI、大模型、AI 大工程、NLP、认知智能、强化学习、深度学习等人工智能方向。上海市人工智能技术标准化委员会委员、上海科委评审专家、中国计算机学会(CCF)高级会员、中文信息学会(CIPS)语言与知识计算专委会委员、中国人工智能学会(CAAI)深度学习专委会委员。申请有数十项人工智能领域的国家发明专利,在国内外知名期刊会议上发表有十多篇学术论文。曾带队获得国内国际顶尖算法竞赛 ACM KDD CUP、EMI Hackathon、“中国法研杯”法律智能竞赛、CCKS 知识图谱评测的冠亚季军成绩。曾获 BroadView2023“技术成长领路人”、2022 年度电子工业出版社博文观点“优秀作者”等称号,2021 年度浦东职工科技创新英才优秀奖。被聘为上海市质量和标准化研究院培训中心企业标准化总监高级研修班教课讲师,高校学生人工智能训练营(同济大学)特邀企业导师,浙江大学中国数字贸易大讲堂讲师团专家。在达观数据致力于将自然语言处理、知识图谱、计算机视觉和大数据技术产品化,以 OCR、文档智能处理、知识图谱、RPA 等产品服务于金融、智能制造、贸易、半导体、汽车工业、航空航天、新能源、双碳等领域。
授课培训案例
1、DataFunTalk:达观数据知识图谱增强的大模型应用实践:https://mp.weixin.qq.com/s/4jvjcMMmJOG1n4F-SKo9-Q
2、CNCC|第六届知识图谱论坛-知识图谱赋能大数据大算力:https://www.ccf.org.cn/Media_list/cncc/2022-11-14/777286.shtml
3、中国计算机学会-基于知识图谱的金融中台架构:https://dl.ccf.org.cn/video/videoDetail.html?_ack=1&id=6169180365834240
4、金融知识图谱的自动化构建:数据集和评测:https://hub.baai.ac.cn/view/9514
5、InfoQ “驯服”不受控的大模型,要搞定哪些事?| 专访达观数据副总裁王文广:https://new.qq.com/rain/a/20240509A04YTG00
6、腾讯云最具价值专家TVP:https://cloud.tencent.com/tvp/member/692
7、数创金融大讲堂-知识图谱与大模型融合应用实践:https://mp.weixin.qq.com/s/l7mXi9MPQJERc15rx8WE8Q


硕士学位 | 天津大学 专业:高性能计算
研究方向:分布式计算、深度学习模型优化、GPU加速计算。
专业领域
华为昇腾技术栈: 深入掌握华为昇腾AI计算平台,包括昇腾算子开发、HCCL集合通信优化、智算集群建设与性能调优。
智算集群建设与优化: 专注于大规模智算集群的设计、部署、设备选型、网络配置及系统集成,提升集群性能和稳定性。
深度学习与高性能计算: 研究和应用分布式训练框架、优化技术,进行大规模计算任务的高效处理。
网络与系统集成: 在复杂网络环境下进行系统集成,确保数据传输的高效性与系统的稳定性。
AI开发框架: 熟悉多种AI开发框架,包括NCE fabric、NCE insight fabric、MindX和ModelArts平台的高阶使用。
学术成就
论文发表: 在国际顶级期刊上发表多篇高影响力研究论文,涉及高性能计算与AI模型优化领域,包括:
《IEEE Transactions on Neural Networks and Learning Systems》:论文集中于深度学习技术在高性能计算中的应用。
《Frontiers in Immunology》:研究了GPU加速技术在生物信息学中的应用。
专利:
“图像分类方法及装置”:改进了图像分类的准确性和处理速度。
“神经网络模型的训练方法及装置”:优化了神经网络模型的训练效率。
国际会议: 多次在国际学术会议上发表演讲,涵盖AI、深度学习和高性能计算领域。
代表性项目经验
-
GFDX智算集群项目
负责内容: 主导智算集群的整体设计与交付,包括设备选型、系统集成和网络设备配置。负责优化集群性能以满足高负载计算需求。
实际项目交付经验: 成功实施了62.5P的智算集群交付,确保系统的高效能和稳定性。
-
首都在线智算集群项目
负责内容: 主导智算集群的设计与部署,负责设备选型、集群网络架构设计和HCCL集合通信的优化配置。
实际项目交付经验: 成功交付了80P的智算集群项目,实现了高效的数据处理和计算能力。
-
北京昇腾人工智能计算中心
负责内容: 领导整个智算集群项目的建设与交付,包括设备选型、系统集成、网络设备配置与调优,以及昇腾平台的算子开发与优化。
实际项目交付经验: 主导了100P的智算集群交付,显著提升了计算能力和系统性能,满足了大规模AI应用需求。
教学与培训经验
昇腾技术培训: 为多家企业和研究机构提供昇腾技术栈的定制化培训,涵盖昇腾算子开发、HCCL通信优化、智算集群建设等内容。
教学方法: 善于将复杂的理论知识与实际应用相结合,通过案例分析与实践操作,帮助学员在短时间内掌握核心技术,并能在实际项目中独立应用。
北京邮电大学本硕连读,拥有扎实的人工智能理论知识和丰富的项目实践经验。在字节跳动和中国银行担任算法工程师,现在在AI科技公司负责大语言模型(LLM)落地项目。已构建自研训练框架,可适配ChatGLM1&2、Baichuan1&2、Qwen14B等主流开源模型的全参/lora/Qlora微调,支持各种训练指标可视化,方便对比实验;已构建训练数据生成流程,基于不同业务需求进行训练数据处理;已构建推理服务,基于自训模型及推理服务成功在APP上线与用户交互。
过往授课课程
-
Python编程与大数据应用
-
ChatGLM与其他LLM的部署、训练与微调
-
LangChain框架深度解析与实践
-
多模态处理与多模态大语言模型实践
-
知识图谱技术在大数据中的应用
-
大模型(LLM)数据预处理与特征工程
LLM培训案例
-
课程内容:讲解LLM的基础原理、部署策略以及微调技巧,帮助学生在实际项目中应用LLM。
-
培训效果:提高了学员对LLM的理解和实际操作能力,促进了项目的顺利进行。
-
课程内容:为技术团队提供LLM模型与多模态AIGC联合应用,利用LLM能力助力多模态生成。
-
培训效果:提升了团队的多模态生成技术水平,增强了企业在AIGC领域的竞争力。
-
中信银行:LLM Driving课程
-
广汽如祺:AIGC大模型应用开发技能培训
个人资质
-
精通Python、Go语言,具有丰富的后端开发经验,涉及数据库、kafka、高并发处理等。
-
具备深厚的大模型、NLP、RAG、思维链CoT、语音识别(ASR)和语音测评(GOP)技术背景,曾基于kaldi和conformer+transformer框架开发相关服务。
-
熟悉主流开源大语言模型的全参/lora/Qlora微调技术,并能够根据不同业务需求进行定制化训练数据处理。
发表论文与发明专利
-
发表论文:《基于多模态大语言模型的智能客服系统研究》《大模型在金融行业的应用与实践》
-
发明专利:一种用于金融风险预测的多模态大语言模型;基于LLM的智能语音交互系统。
其他项目经验
-
项目内容:负责后端开发,涉及数据库管理、kafka消息队列、高并发处理等技术。
-
项目成果:提高了系统的稳定性和处理效率,满足了高并发需求。
-
项目内容:基于kaldi框架训练语音测评模型,实现服务端和手机端本地化推理。
-
项目成果:该服务成功应用于用户APP的中英文口语练习,实现了自动化打分评价。
-
项目内容:基于conformer+transformer框架训练端到端模型,实现服务端离线识别和流式识别。
-
项目成果:该服务成功应用于客服系统和语音审核场景,提高了识别准确率和效率。
-
Python&Go语言后端开发
-
语音测评(GOP)服务
-
语音识别(ASR)服务
客户反馈


部分授课课件



前微软亚洲研究院NLP研究员;
TGO鲲鹏会AIGC、AGIA社区核心成员;
工信部人工智能应用高工认证;
阿里云MVP;
前高顿教育CTO;
行业AI培训案例
国家电网工建部及上海各区分公司 ——《ChatGPT人工智能在项目管理中的技术应用》
百亿量化私募基金白鹭资管 ——《GPT在量化私募行业的技术应用》
独立基金销售机构基煜基金 ——《GPT在金融行业的技术应用》
上海头部人力资源背调公司猎查查 ——《LLM在人力资源管理行业的技术应用》
TGO鲲鹏会AI数智化转型主题培训 ——《LLM在企业数智化转型中的技术应用》
浦软孵化器AI&元宇宙主题培训 ——《大语言模型在toB业务场景中的技术应用》
TGO鲲鹏会AGIA社区主题培训 ——《LLM在数字员工产品中的技术应用》
万商俱乐部AI赋能商业主题培训 ——《ChatGPT的前世今生》
培训现场画面

中科院计算机博士,现任北京邮电大学计算机学院硕导,多模态内容分析及多模态大模型研究领域的专家。景行博士在多模态数据处理、机器学习和人工智能方面拥有丰富的研究经验和技术成果,致力于推动大模型技术在多个行业的应用,积累了深厚的理论基础和实践经验。
教育背景
-
2016.09—2020.06 中国科学院大学 计算机科学与技术 博士
可讲主题及培训内容
-
多模态内容分析技术与应用
-
大模型架构设计、优化与部署
-
计算机视觉与深度学习
-
自然语言处理与多模态融合
-
智能推荐系统与个性化服务
-
数据挖掘与机器学习
培训案例
-
中国电信:主持“大数据平台优化及开发应用实战”培训,提升了电信网络运维及开发团队的大数据应用实践能力,优化了多个数据分析应用软件的性能。
-
华为技术有限公司:开展“智能推荐系统与个性化服务”培训,提升华为研发团队在大数据处理和个性化推荐系统设计上的技术水平。
-
中科院软件研究所:负责“多模态内容分析技术及应用”培训,促进了科研团队在多模态数据处理和分析方面的技术提升。
-
京东集团:进行“计算机视觉与深度学习”培训,帮助京东AI团队在图像识别、物品分类等方面实现了技术突破。
个人资质
-
高级工程师职称
-
多模态内容分析及大模型技术专家
-
IEEE高级会员
-
ACM会员
-
发表SCI论文10篇,EI会议论文7篇
-
作为项目负责人主持国家自然科学基金、省部级重点研发项目多项
发表论文与发明专利
-
发表在《IEEE Transactions on Circuits and Systems for Video Technology》的论文“Multimodal Content Analysis and Applications”
-
发表在《Pattern Recognition》的论文“Advanced Techniques in Image Recognition”
-
发表在《Neural Computing and Applications》的论文“Neural Networks in Multimodal Data Processing”
-
发表在《Neurocomputing》的论文“Deep Learning Models for Multimodal Data”
-
发表在《Multimedia Tools and Applications》的论文“Tools and Techniques for Multimedia Data Processing”
-
发表在NeurIPS、AAAI、ACM MM等顶级会议的多篇论文
-
“一种基于多模态数据分析的智能推荐系统”发明专利
-
“大规模数据处理与优化方法”实用新型专利
-
论文:
-
专利:
网易技术总监丨有道语音交互技术负责人 | 网易集团技术委员会 音视频分委会秘书长。
信号与信息处理方向博士,人工智能&大模型方向,发表高质量学术论文10余篇,授权专利10余件。目前聚焦在打造更极致好用的AI语音/大模型/AI老师解决方案。
博士(硕博连读)2005-2010
• 中国科学院声学研究所语言声学与内容理解重点实验室
(中科信利),信息与信号处理
• 课题:鲁棒语音识别的若干技术研究
• 发表学术论文SCI等10余篇
网易有道信息技术(北京)有限公司,2019.01-至今
• 基于LLM+Agent打造AI老师,子曰大模型的研发&落地
• 组建语音团队,强力支撑集团内外众多明星项目产品
• 北京联想软件有限公司,2013.01-2018.12
• 联想研究院语音技术负责人,打造国内首个免触语音拨号/接听、拍照产品方案,推出自研语音交互解决方案。
16年产业数字化和智能化技术背景,北京航空航天大学计算机仿真专业硕士,挪威工作两年,连续创业者,深谙金融企业的数字化技术路线。
AIGC知名创新企业墨见MoLook创始人和CEO,阿里云前解决方案总监,负责基于云计算、AI、IoT的产品和解决方案沉淀、业务拓展、生态建设,挪威软件公司Prediktor前中国区负责人,ICA联盟工作组组长,阿里云CIO学院讲师。连续3年阿里云产品销售额1亿+,曾服务于陕煤、美孚、中国国网、南方电网、中烟、上海电气、宝钢、物产中大、东方希望等客户。
擅长AIGC的视觉和文本技术,作为多个AIGC项目的负责人,对AI技术在企业落地方面有丰富的经验和深刻的见解。
AI创业公司的LLM项目已落地南信投、欧冶、中烟等企业。视觉项目已落地苏美达、三彩、雅戈尔等企业。
其中南信投、欧冶、宏川等都是金融向公司,林琚率领墨见为这几家公司提供了完整的AIGC解决方案,包括基础大模型、知识库RAG、工作流等方面的技术和应用落地。南信投(资金投资)作为江苏第一大国资金融集团,墨见帮助其搭建AI大模型应用平台,并打造智慧办公、数字员工等应用,与其数字化系统紧密结合。欧冶作为贸易金融公司,墨见帮助其打造票据审核、知识库等金融服务应用。
林老师深谙云计算、大数据、物联网、AI等技术原理和路径,以及在企业落地实现的方式。是技术落地企业的实战派。作为互联网产品解决方案负责人,林琚参与规划与建设了超过300个企业数智化项目,其中包括30个大规模项目,实战经验丰富。作为AIGC公司的创始人,对AI技术以及AI在企业的应用有深度理解。
过往授课主题及培训内容
-
大模型的基本原理与架构
-
主要大模型框架与技术应用
-
金融数据分析与建模
-
风险控制与预测
-
客户行为分析与推荐系统
-
多模态数据融合技术
-
图像、文本与语音数据的综合处理
-
大模型技术基础
-
大模型在金融行业的应用
-
多模态内容分析
LLM产品研发和培训案例
-
以外部核心技术身份参与金融科技企业研发项目,研发基于大模型的金融风险预测系统,成功提升了风险控制的准确性和效率。
-
为该企业技术团队提供大模型技术辅导和培训,覆盖数据预处理、模型训练与优化等内容。
-
主持开发基于多模态内容分析的客户行为分析系统,为银行提供个性化推荐服务。
-
对银行相关部门进行系统使用与大模型技术应用的培训,促进了新技术在实际业务中的落地。
-
与南信投合作开发金融大模型应用平台,推动大模型在金融行业的广泛应用。
-
提供针对内部技术人员的专项培训,涵盖大模型开发与应用的各个环节。
-
合作开发:金融风险预测系统
-
合作开发:客户行为分析与推荐系统
-
南信投:金融大模型平台合作项目
毕业于中国科学技术大学自动化系,拥有20+年IT/AI经验,先后在IBM、华为、顺丰、KPMG等知名企服务于DBS,UBS,HSBC等大型银行客户。2023年起All in生成式AI应用创业,专注于金融领域的AI咨询、系统实施和培训。精通生成式AI相关技术栈和应用系统设计开发。
2023.10-至今:生成式AI研发专家
-
持续跟踪国内外开源和闭源大模型的发展动态,进行本地部署或通过API集成到系统,熟悉GPT, Claude, Gemini, Llama, Mistral, Command R, GLM, Qwen, Deepseek, Moonshot, Xunfei Spark, Ernie, Yi, MiniMax等模型,能够根据金融行业不同的业务场景进行模型选取
-
熟悉大量开源嵌入模型和向量数据库,如BGE, Jina, Nomic等系统嵌入模型和Qdrant, Milvus, Chroma, LanceDB, Fincore等向量数据库,并能提供选型建议
-
熟练掌握Langchain, Llamaindex, Langgraph等生成式AI应用开发框架,并能根据金融行业的业务场景选型和应用
-
研究了多个开源和闭源平台级产品,包括Coze, DSPy和各模型厂商提供的在线chatbot和智能体平台等
-
设计开发了多个生成式AI应用,从简单的多轮对话聊天机器人,到RAG、Agent、Agentic Workflow还有Vscode代码生成插件和浏览器插件;精通生成式AI应用系统架构设计和系统调优
-
部署了stable-diffusion模型进行文生图能力评估测试,同时持续跟踪国内外文生图模型和平台发展, 熟悉国内厂商文生图平台及API
-
部署并在系统种集成了speech-to-text和text-to-speech的模型,如Whisper, EmotiVoice
-
进行了多场大模型技术应用培训,包括对金融行业的IT团队进行的“AIGC大模型技术在金融领域的场景化应用“培训。
2017-2023,KPMG中国智能创新中心技术负责人
创建了KPMG中国智能创新中心,管理着从设计、开发、交付、上线到运维的全流程,团队规模将近500人。带领团队面向公司内外部客户设计和开发人工智能、大数据驱动的解决方案,围绕信用、风险、合规等业务领域构建知识库、算法模型和业务系统。服务的客户包括国内外知名企业,如HSBC,平安集团、招商银行、太平洋保险、蚂蚁金服等等。
2001-2014,IBM,从技术开发到业务管理
作为技术团队负责人,带领团队进行应用系统设计、开发、测试、上线和运维;服务的客户包括:PCCW、DBS、国泰航空、UBS、UPS、深圳机场物流园等。
过往相关案例
|
训练营名称 |
培训周期 |
培训内容 |
服务客户 |
|
Nvidia全系技术栈培训-技术架构、智算平台、算力中心建设 |
14天 |
详尽解析英伟达技术体系,包括DGX、HGX、GPU技术及IB网络架构,及其在智算平台中的应用。不论是面向AI开发框架的深入了解,还是大模型的端到端调优,线上及线下双模式培训都将提供丰富的实操经验。让企业在英伟达系统中,提升大模型性能,优化智算中心的设计与运维,精通存储和网络基础设施的构建。 |
某智算集群建设厂商 |
|
从训练到推理,LLM大模型技术培训 |
6天 |
内容全面揭示大模型技术的核心原理与应用。深入探讨大模型从理论到实践的每一个环节,包括大模型的理论基础、关键技术如分布式并行计算、训练加速技术,以及推理优化技术。 |
中国石油数据中心 |
|
RAG&CoT深度技术课程 |
2天 |
《RAG&CoT深度技术课程》是为某IT软件上市公司的AI系统开发团队定制研发的高级培训课程,旨在深入讲解大语言模型(LLM)领域的两大前沿技术:RAG(Retrieval-Augmented Generation)和思维链(Chain of Thought, CoT)。本课程通过理论与实践相结合的方式,详细介绍RAG和CoT技术的基本原理、应用场景、技术实现方法以及最新的研究进展,帮助学员全面掌握这些技术的核心要点。 |
新致软件 |
|
LLM大模型技术内训 |
4天 |
本次培训项目是为华南某大型商业银行研发中心的产品经理、研发工程师、算法工程师定制开发的全面的大模型知识及其在金融行业中的应用培训和课题研讨。通过本次课程,学员深入了解了大语言模型(LLM)的基本原理、应用场景、案例分析以及实际操作技巧,从而在需求沟通和产品设计中能够更好地运用大模型技术。 |
广发银行 |
|
高性能计算环境下的算力集群规划与优化 |
12天 |
本课程旨在为数据中心的运维工程师、IT工程师提供一套全面且深入的培训,涵盖从算力集群的规划与设计、POC环境的搭建,到GPU、CUDA、算力模型、应用调优、应用性能监测、算力调度管理、网络调优和安全保障等多个关键领域。整个课程注重实操,旨在提升学员的动手能力,使其能够在实际工作中高效地管理和优化高性能计算环境。 |
某智算集群建设厂商 |

TsingtaoAI拥有一支高水平的产学研一体的AI产品开发团队,核心团队主要来自清华大学、北京大学、中科院、北京邮电大学、复旦大学、中国农业大学、美团、京东、百度、中国技术创业协会和三一重工等产研组织。TsingtaoAI核心团队专长于算力、行业LLM/AIGC应用的产品研发,面向企业的大语言模型应用落地等业务,如面向智能客服、教育、人力资源、电商和轨道交通等行业领域的LLM和AIGC应用开发。公司拥有近10项LLM/AIGC相关的知识产权。
TsingtaoAI自研基于LLM大模型的AIGC应用开发实训平台、基于LLM大模型的AI通识素养课数字人助手、面向CS专业的AI训练实训平台和基于大语言模型的AIGC案例学习平台,聚焦虚拟现实、金融科技、医药健康、高端装备、新能源、新材料、节能环保、文化创意、农业科技和食品科技等关键行业,通过链接全球数以千计的关键领域的AI科学家和工程师,为央国企、上市公司、外资企业、政府部门和高校提供AI企业内训和高校实训服务。

